개발하는 리프터 꽃게맨입니다.
[C++/자료구조] 자료구조에서의 좋은 해쉬함수 본문
좋은 해쉬 함수가 뭔데?
자료구조에서의 해쉬 함수는 키 값을 이용해 해쉬 주소를 얻어낼 수 있는 함수를 뜻하며
이는 엄밀하게 정해져있는 것이 아니라, 프로그래머가 상황에 따라 재량껏 정의하여 사용합니다.
여기서 나쁜 해쉬 함수와 좋은 해쉬 함수는 엄연히 다릅니다.
좋은 해쉬함수가 되기위한 조건을 몇 가지 살펴보도록 하죠.
1) 좋은 해쉬 함수의 조건
(1) 해쉬 함수의 값이 해쉬 테이블 전체에 균일하게 분산되어야 한다.
해쉬에서는 키 값이 균일하게 분산되어 있을수록 좋습니다.
키 값이 균일하게 분산되다는 것이 곧 충돌이 적어짐을 뜻하죠.
(2) 충돌 발생 빈도가 적어야 한다.
(3) 연산이 빨라야 한다.
너무 연산량이 많은 해쉬의 경우에는 데이터 접근 속도가 느리기 때문에 좋은 해쉬함수라고 할 수 없습니다.
그래서 암호학적 해쉬는 자료구조 해쉬에서 쓰기 어려운 것이죠.
해쉬 함수를 만드는 기법
1) 모듈러
나머지 연산을 이용하여 해시를 만드는 방법입니다.
해쉬 테이블의 버켓 수가 m이라고 하고, 키를 k라고 할 때,
h(k) = k mod m
과 같은 식으로 구하는 방법이죠.
이 때, m 값에 따라서 충돌 빈도가 달라지는데,
2의 제곱수에 가깝지 않은 소수 m를 선택하는 방법입니다.
closed hashing 기법을 사용하고 사용할 키의 수가 1500개 정도라고 가정할 때,
적재율을 0.5 언저리로 설정하고, 2의 제곱수인 2048 에서 가깝지 않은
3000 언저리의 소수를 사용하면 되겠습니다.
2) 경계 접기
경계접기는 다음과 같은 과정으로 동작합니다.
해쉬 테이블의 크기를 999, k = 12391258 라고 할 때,
(1) 키를 해쉬값의 자리 수로 분할한다.
123 / 912 / 58
(2) 분할한 값의 짝수 부분을 역으로 정렬한다.
123 / 219 / 58
(3) 분해된 키들을 더한다.
123 + 219 + 58 = 400
(4) 테이블 크기로 모듈러한다.
400 % 999 = 400
3) 이동 접기
이동접기는 다음과 같은 과정으로 동작합니다.
해쉬 테이블의 크기를 999, k = 12391258 라고 할 때,
(1) 키를 해쉬값의 자리 수로 분할한다.
123 / 912 / 58
(2) 분할한 값을 모두 더한다.
123 + 912 + 58 = 1093
(3) 테이블 크기로 모듈러한다.
1093 % 1000 = 93
4) 중간 제곱
키 값을 제곱한 다음 중간 몇개의 값만 가져옵니다.
해쉬 테이블의 크기가 100이라고 하면
1~2 자리 값을 골라서 가져올 수 있습니다.
키 값이 218 라고 하면,
218 * 218 = 47,524 이고
로직에 따라서 75, 5, 52 아니면 752 % 테이블크기
와 같이 사용하면 되겠습니다.
정수 해쉬 함수
1) 모듈러 해쉬 함수

2) Knuth 변형 모듈러 해쉬 함수
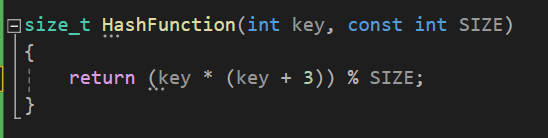
일반적인 모듈러 해쉬 함수보다 조금 더 좋게 작동합니다.
3) knuth 곱셈 해쉬 함수

A의 값에 따라 성능이 달라지며
Knuth에 따르면 A는 (루트(5) - 1)/2 일 경우 최적이라고 말합니다.

size_t HashFunction(int key, const int SIZE)
{
// double A = 0.5 * (std::sqrt(5) - 1);
float A = 0.61803f; //오버헤드 때문에 미리 계산된 값을 사용
float s = key * A;
float x = s - ::floor(s);
return static_cast<size_t>(::floor(SIZE * x));
}
문자열 해쉬 함수
문자열을 해쉬할 때 좋은 함수들을 소개합니다.
1) lose lose 해쉬
가장 간단하고 단순한 문자열 해쉬 함수입니다.
그렇게 성능이 좋은 해쉬함수는 아닙니다.

2) sdbm 해쉬
좋은 분포를 갖는 문자열 해시 함수 중 하나입니다.

size_t HashFunction(const char* str)
{
size_t hashAddr = 0;
int c;
while (c = *(str++))
hashAddr = c + (hashAddr << 6) + (hashAddr << 16) - hashAddr;
return hashAddr;
}
3) djb2 해쉬
매우 유명한 문자열 해쉬 함수입니다.

size_t HashFunction(const char* str)
{
size_t hashAddr = 5381;
int c;
while (c = *(str++))
hashAddr = ((hashAddr << 5) + hashAddr) + c;
return hashAddr;
}
문자열 해쉬 함수는 앞서 소개한 함수들 말고 좋은 함수들도 많으니 관심있으면 추가적으로 공부해보시길 바랍니다.
'자료구조 > 자료구조 이론' 카테고리의 다른 글
| [C++/자료구조] 이차조사법과 이중해쉬 (Quadratic Probing, Double Hash) (0) | 2024.01.26 |
|---|---|
| [C++/자료구조] 선형조사법과 체이닝 해쉬 (1) | 2024.01.26 |
| [C++/자료구조] 해쉬 입문 (1) | 2024.01.25 |
| [C++] 자가 균형 트리: 레드블랙 트리 (上: 삽입전략) (0) | 2024.01.24 |
| [C++] 자가 균형 트리: AVL 트리 (0) | 2024.01.23 |



