1. 해쉬란?
1) 개요
탐색에 있어서 매우 강력한 자료구조입니다.
앞서 살펴봤던 배열, 연결리스트의 경우 삽입/삭제/탐색 에 있어서 O(N)
트리 기반 자료구조의 경우 삽입/삭제/탐색 에 있어서 O(log2 N) 의 시간 복잡도가 소요됩니다.
하지만 해쉬의 경우 O(1) 라는 매우 빠른 시간에 삽입/삭제/탐색을 수행할 수 있죠.
그런데, 어떻게 이런 일이 가능할까요?

해쉬는 키를 해쉬함수를 통해 유의미한 정수로 바꿉니다.
그리고 해쉬테이블에 데이터를 저장하죠.
이런 일련의 과정을 해싱이라고 합니다.
잘 이해가 안가신다면 이렇게 생각해보세요.

사이즈 100의 배열이 있고,
우리가 접근하고 싶은 데이터의 주소를 알고있다면
바로 접근이 가능하잖아요?
이것을 기본 개념으로 출발합니다.

key값을 해쉬테이블을 이용해서,
해쉬테이블에 접근할 수 있는 유의미한 index로 만들어서
한 번에 접근하는 방법입니다.
간단하죠?
이러면 O(1) 만에 접근, 삭제, 탐색이 가능합니다.
동일한 키에 대해서는 동일한 index를 만들어 내기 때문이죠.
2) 용어 정리
해쉬테이블: 데이터가 저장되어 있는 자료구조를 뜻하며, (키, 값) 의 쌍을 저장합니다.
해쉬함수: 키를 산술적인 연산을 통해 해쉬 테이블에 접근할 수 있는 색인으로 바꿔주는 함수입니다.
키: 해쉬테이블에 접근할 수 있는 값입니다.
3) 예시

C++에서는 해쉬가 unordered_map 이라는 STL로 구현되어 있습니다.
해당 해쉬는
string 을 키로, int 를 값으로 저장하고 있죠.
그러면 string 을 통해 int 데이터로 접근할 수 있다는 것을 뜻합니다.
가령, "콜라"라는 string으로 hashTable에 접근하고자 한다면,
"콜라"를 해쉬함수에 넣어서, 유의미한 색인을 얻어냅니다.
그리고 hashing 내부에 있는 해쉬테이블에
키값을 이용해 얻는 색인을 통해서 적절한 index로 접근하여
자료를 삽입, 삭제, 수정, 탐색 할 수 있습니다.
무려 O(1)이라는 매우 빠른 속도로 말이죠.
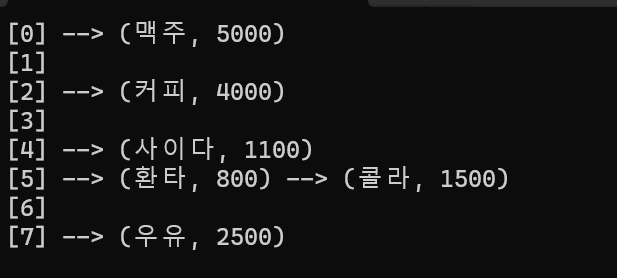
내부 해쉬 함수가 어떻게 생겼는지는 알 수 없지만
"커피"를 넣으면 내부에서 잘 분석해서,
'2'라는 색인으로 바꾼 뒤
해 내부의 해쉬테이블[2] 로 접근해서, (커피, 4000) 의 쌍을 저장, 접근 하는 것을 볼 수 있습니다.
2. 해쉬의 구조
1) 기본적인 아이디어
해쉬의 기본적인 아이디어부터 다시 출발해보겠습니다.
만약 어떤 음료수 개수가 100개라고 한다면, 음료수에 그 가격을 가장 빠르게 탐색하는 방법은
각각 음료주마다 ID 를 붙이고 100개짜리 배열을 만들어서, ID에 해당하는 배열의 index에 저장하는 것입니다.
이 연산은 명백하여 O(1) 입니다.
그런데,
만약 키가 정수가 아니라면 어떻게 되나요?
아니면 너무 큰 숫자라면 어떻게 될까요?
이런 경우에 해시 함수를 사용합니다.
키를 해시 함수에 넣어서 해시 주소를 생성한 다음에, 그것을 해시주소로 사용하는 것이죠.
위에서 보았듯
"콜라"라는 키를 해시함수에 넣어서 "2"라는 해시주소를 얻어냈고,
2로 해시테이블에 접근해서, (키, 값)의 쌍을 저장 및 접근하는 것입니다.
2) 해쉬의 문제점
이상적인 해쉬는 항상 O(1) 만에 해쉬 테이블로 접근할 수 있는 해쉬를 뜻합니다.
예를 들어 100개의 음료수가 있다고 할 때,
100개의 배열을 선언해서, 딱딱맞게 음료수를 꽉꽉 채워넣고
적당한 ID만 입력하면 O(1)만에 바로 원하는 해쉬 테이블로 접근할 수 있으면 모든게 아름답다워지는 것이죠.
그러나 실제 해쉬는 그렇지 않고, 여러가지 문제점을 가지고 있습니다.
(1) 과도한 메모리 소모
만약 1~99 사이의 ID를 가지는 음료수 이름과 가격을 매핑한다고 상상해봅시다.
예를들어 1, 11, 83, 99 음료수 단 4개만 저장한다고 했을때
크기가 100인 배열을 생성해야겠죠?
그런데 4개의 음료수만 저장할 뿐인데, 너무 과도한 크기의 메모리를 소모하는 것 같지 않나요?
해쉬의 단점은 다른 자료구조에 비해 공간 복잡도가 크다는 것에 있습니다.
이진탐색트리 기반의 자료구조의 경우 10개의 데이터 저장에 10개의 공간만 필요로 하죠.
그러나 해쉬의 경우 그 이상의 공간을 필요로 합니다.
이것을 그나마 해결하는 방법은 좋은 해쉬함수를 사용하는 것이죠.

위 해쉬함수가 절대 좋은 해쉬함수는 아니지만,
해쉬 함수를 통해 7개의 메모리만 사용해서 데이터를 저장하는 모습입니다.
만약 이런 함수가 없다면 어쩔 수 없이 많은 데이터 공간을 소모할 수 밖에 없는 것이죠.
비록 이런 식으로 해도 불필요한 메모리를 사용할 수 밖에 없습니다.
최대한 줄이는 것이 최선인 것이죠.
(2) 충돌

이 해쉬함수를 살펴봅시다.
HTCapacity가 7이라고 했을 때,
name 으로 5가 들어온 경우랑, 12가 들어온 경우랑 동일하게 5가 리턴됩니다.
다른 x 값에 대해서 동일한 해쉬 주소를 리턴한다는 뜻은 곧 충돌이 발생한다는 것이 됩니다.
이러면 동일한 위치에 데이터를 집어넣으면 이전 값을 덮어쓰기 때문에 예전에 저장했던 값이 없어지고..
예측하지 못하는 결과가 나오는 상당히 어지러운 상황이 벌어지는 것이죠.
이를 해결하기 위한 방법은
해쉬 테이블의 구조 자체를 바꾸거나, 충돌이 덜 발생하는 해쉬 함수를 사용하는 것입니다.
전자는 나중에 다른 포스팅으로 다룰 것이고,
후자도 역시 그렇지만, 적어도 위 사진에 있는 해쉬함수는 절대 좋은 해쉬함수가 아니라는 것만 알아주시면 됩니다.
아무래도 좋은 해쉬함수라는 것은 어떤 값이 들어와도, 한정된 공간에 데이터를 골고루 뿌려주는 함수를 뜻합니다.
앞으로 설명할 여러가지 해쉬 구조와 해쉬 함수들은
한정된 데이터 공간 안에서 충돌을 최소화하려는 노력이라고 이해하시면 되겠습니다.
3. 마무리
아무래도 다뤄야할 해쉬 구조와 해쉬 함수가 많으므로
다음 포스팅에 하나하나 씩 다뤄보도록 하겠습니다.
'자료구조 > 자료구조 이론' 카테고리의 다른 글
| [C++/자료구조] 이차조사법과 이중해쉬 (Quadratic Probing, Double Hash) (0) | 2024.01.26 |
|---|---|
| [C++/자료구조] 선형조사법과 체이닝 해쉬 (1) | 2024.01.26 |
| [C++] 자가 균형 트리: 레드블랙 트리 (上: 삽입전략) (0) | 2024.01.24 |
| [C++] 자가 균형 트리: AVL 트리 (0) | 2024.01.23 |
| [C++] 트리와 이진 탐색 트리 (Binary Shearch Tree) (0) | 2024.01.23 |