
개발하는 리프터 꽃게맨입니다.
[C#] C#에서 구현하는 객체지향 본문
스스로 공부한 내용을 정리없이 구어적으로 풀어쓴 포스팅입니다.
오로지 제가 볼 기준으로 정리한 글이기에
참고하는 것을 추천하지 않습니다.
[객체 지향이란?]
객체란 속성과 기능을 가진 구체적은 인스턴스를 말합니다.
속성과 기능을 C#코드로 표현할 수 있을까요?
속성은 데이터로, 기능은 메소드로 표현하면 됩니다.
객체지향 프로그래밍에서 가장 중요한 역할을 하는 것은 클래스입니다.
클래스는 객체를 만들기 위한 청사진인데, 객체를 만들기 위해서 어떤 속성과 기능을 가져야하는지
명시된 설게도라고 생각할 수 있습니다.
클래스는 객체가 가지게 될 속성과 기능을 정의하지만 실체를 가지지 않습니다.
이런 클래스로 만든 객체가 실체를 가지고 독립적인 메모리 공간을 차지합니다.

모든 클래스는 복합 데이터 형식입니다.
복합 데이터 형식은 참조 형식입니다. (즉, 참조하고 있는한 프로그램이 끝날 때 까지 계속 살아있음)
그러므로 지역변수 player는 new Player()로 인해 할당된 메모리를 가리킬 뿐입니다.
new 연산자와 생성자를 이용해서 힙에 객체를 생성하고, player 는 생성자가 힙에 생성한 객체를 가리킨다.
[생성자와 소멸자]
객체가 생성될 떄는 생성자가 호출되고 소멸할 떄는 소멸자가 호출됩니다.
생성자는 클래스와 이름이 같고 반환 형식이 없습니다.
생성자의 임무는 단 한 가지, 해당 형식의 객체를 생성하는 것 입니다.
생성자를 구현하지 않아도 컴파일러에서 자동으로 생성자를 만들어 주는데,
이런 생성자를 기본 생성자라고 합니다.
객체 생성과 동시에 데이터 필드의 값을 초기화하고 싶다면 생성자를 커스텀해서 만들 수 있습니다.
생성자는 오버로딩이 가능하기 때문에 다양한 형태의 생성자를 준비할 수 있습니다.
그런데 사용자 지정 생성자를 사용하면 컴파일러는 기본 생성자를 제공하지 않습니다.
[소멸자]
소멸자는 생성자와는 달리 매개변수도 없고, 한정자를 사용하지도 않습니다.
또한 오버로딩도 불가능하며 직접 호출할 수도 없습니다.
소멸자는 CLR의 가비지 컬렉터가 객체를 소멸되는 시점을 판단해서 소멸자를 호출합니다.
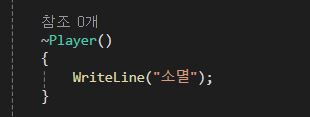
C++ 과 달리 언제 소멸할지는 예측할 수 없ㅅ브니다.
CLR의 가비지 컬렉터는 치워야 할 쓰레기가 일정 양에 이르러야 동작합니다.
그런데 쓰레기가 차오르는 시간을 정확하게 알 수 없고, 따라서 가비지 컬렉터가 동작할 시점도 알 수 없습니다.
종료자를 명시적으로 구현하면 가비지 컬렉터는 클래스의 족보를 타고 올라가 객체로부터 상속받은 Finalize() 메소드를 호출합니다. 그런데 이렇게 하면 응용 프로그램의 성능 저하를 초래할 확률이 높아 권자앟지 않습니다.
종료자를 구현하지 말아야 할 가장 중요한 이유가 있는데, 그것은 바로 CLR의 가비지 컬렉터는 우리보다 훨씬 더 똑똑하게 객체의 소멸을 처리할 수 있다는 것입니다. 생성은 생성자에, 뒤처리는 가비지 컬렉터에 맡기는 편이 좋습니다.
다시 한 번 말하지만
객체의 소멸을 담당하는 가비지 컬렉터는 언제 동작할지 모릅니다.
심지어는 어떤 객체를 어떤 순서로 소멸시킬지에 대한 보장도 없습니다.
그래서 C++에서 사용하는 소멸자를 이용한 테크닉은 사용할 수 없다고 봐도 무방합니다.
[정적 필드와 메소드]
C#에서 static은 메소드나 필드가 클래스의 인스턴스가 아닌 클래스 자체에 소속되도록 지정하는 한정자입니다.
즉, static 멤버는 객체마다 독립적으로 가지는 것이 아니라
클래스 자체가 유일하게 가집니다.
한 프로그램 안에서 객체는 여러 개가 존재할 수 있으나 클래스는 단 하나만 존재합니다.
똑같은 클래스가 두 개 이상 존재할 수는 없습니다.
즉, static 필드는 프로그램 내에서 유일하게 존재합니다.
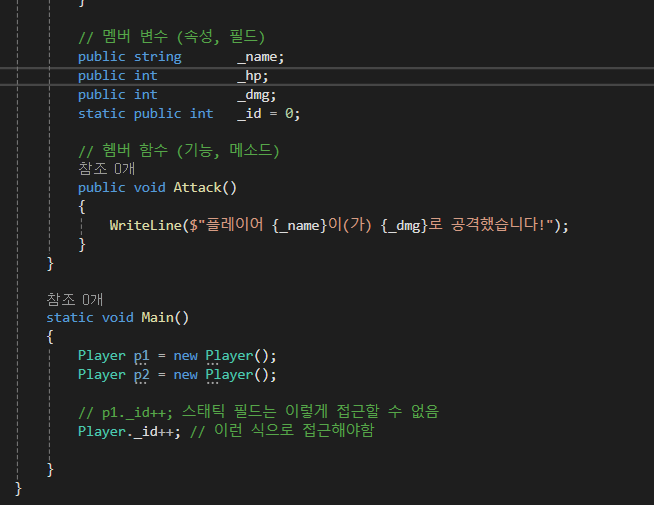
접근 방법도 다릅니다.
static으로 수식한 필드는 프로그램 전체에 걸쳐 하나밖에 존재하지 않습니다.
프로그램 전체에 걸쳐 공유해야 하는 변수가 있다면 정적 필드를 이용하면 됩니다.
정적 메소드의 반댓말
즉, 인스턴스를 생성해야만 접근할 수 있는 필드의 경우
인스턴스 메소드, 인스턴스 데이터 필드 등.. 이라고 부릅니다.
별도의 인스턴스 생성 없이 호출하고 싶은 메소드는 정적으로 선언할 수 있고
아니라면 인스턴스 필드로 선언할 수 있습니다.
[얕은 복사와 깊은 복사]
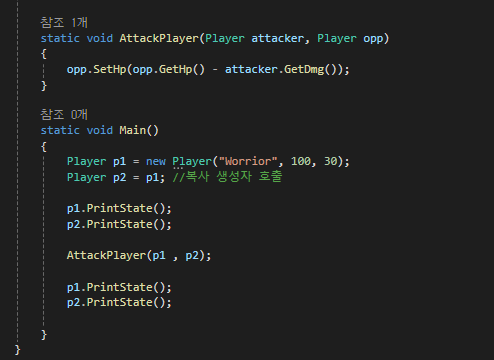
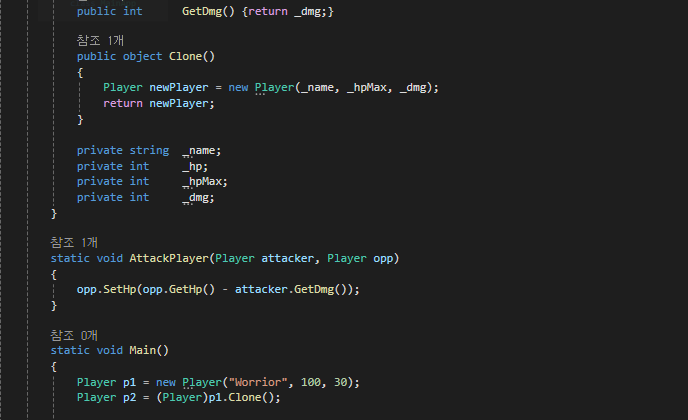
p1의 clone으로 p2를 만들었다고 생각해봅시다.
여기서 p1의 공격력 30으로 hp 100인 p2를 때리면
p2의 피가 70으로 감소되야 할겁니다.
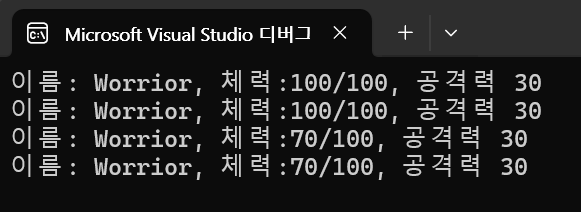
그런데 p1의 체력도 감소된 것을 볼 수 있습니다.
클래스는 태생이 참조 형식이기 때문입니다.
두 p1, p2는 동일한 힙 메모리를 가리키고 있습니다.
만약 p1의 정보를 그대로 p2를 만들어내고 싶으면
독립적인 힙 메모리 영역을 만들어 줘야만 합니다.
현 예제처럼 같은 메모리 공간을 가리키도록 복사하는 것은 얕은 복사
원하는 바처럼 복사를 하되 완전히 독립된 메모리 공간을 만들도록 하는 것을 깊은 복사라고 합니다.
안타깝게도 C#에서 깊은 복사를 자동으로 해주는 구문은 없기 때문에
직접 만들어야 합니다.
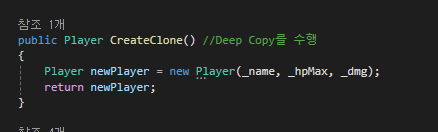
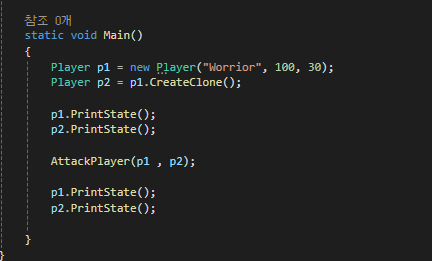
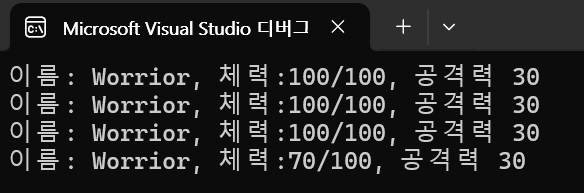
[ICloneable.Clone() 메소드]
System 네임스페이스에는 ICloneable 이라는 인터페이스가 있습니다.
인터페이스는 '클래스가 구현해야 하는 메소드 목록'을 뜻하며,
특정 메소드를 반드시 구현하도록 강제합니다.
만약 깊은 복사 기능을 가질 클래스가 .NET의 다른 유틸리티 클래스나 다른 프로그래머가 작성한 코드와 호환되로고 하고 싶으다면 ICloneable 을 상속하는 것이 좋습니다.
[this 키워드]
자기 자신을 지칭하는 키워드
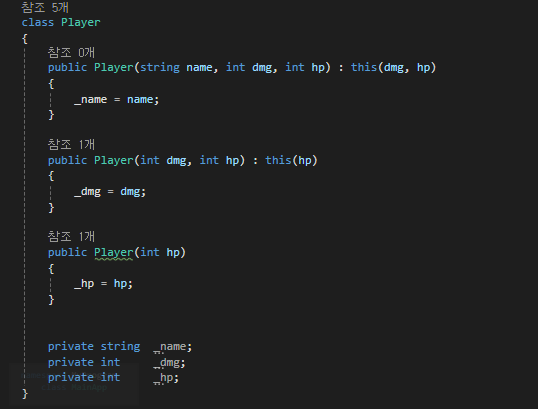
[this 생성자]
생성자 오버로딩에 있어 코드 중복을 피하기 위한 테크닉
this로도 생성자를 호출할 수 있습니다!

[은닉성 - 접근 한정자]
접근 제한과 관련된 한정자로 총 6개 존재합니다.
public - 전역적으로 접근할 수 있음
protected - 클래스 내부 및 자식 클래스에서 접근할 수 있음
private - 클래스 내부에서만 접근할 수 있음, 자식도 접근 불가
internal - 해당 프로젝트에서만 public 으로 접근할 수 있음
protected internal - 해당 프로젝트에서만 protected 로 접근할 수 있음
private internal - 해당 프로젝트에서만 private 로 접근할 수 있음
기본적으로 default한 한정자는 private 자동 지정
[상속성]
기본 클래스와 파생 클래스를 이용한 상속 기능 구현
생성할 떄 부모 -> 자식 순으로 생성자 호출
소멸자는 자식 -> 부모 순으로 호출
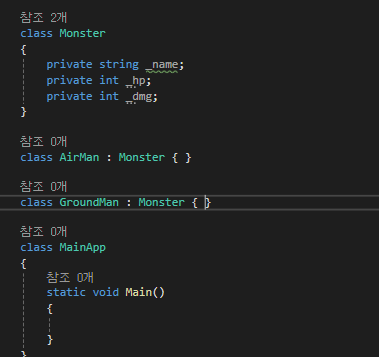
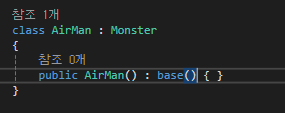
부모를 지칭할 수 있는 base라는 키워드 존재합니다.
C#는 인터페이스를 제외하고 클래스 다중 상속을 할 수 없고
즉, base는 모호함을 가지지 않습니다.
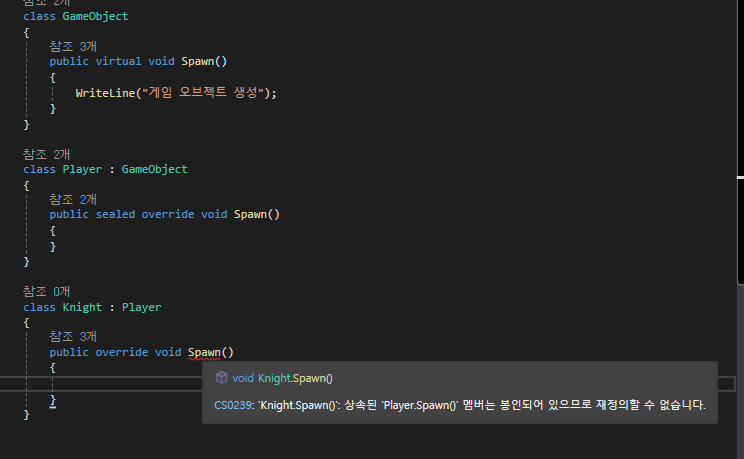
[sealed 한정자]
특정 클래스에 대해서 파생 클래스 생성을 의도적으로 막고 싶다면 sealed 한정자를 사용할 수 있다.
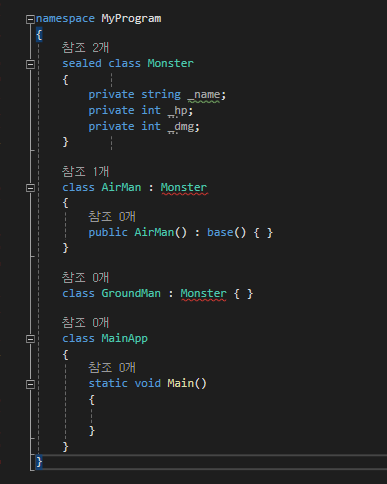
그럼 '상속 봉인'이라는 현상이 발생한다.
[캐스팅]
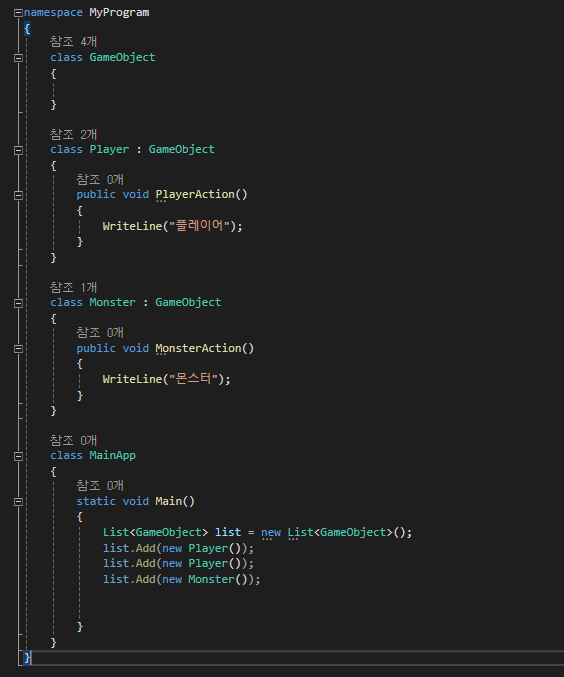
Player와 Monster는 GameObject 입니다.
Player is Player와 Monster is Monster 는 맞는 말이지만,
Player is GameObject 와 Monster is GameObject 역시 맞는 말 아닌가요?
그래서 GameObject는 Player와 Monster 둘 다 품을 수 있습니다.
위 코드에서 list[0]가 가리키는 실제 메모리에 저장된 객체는 Player 이지만,
list[0]자체는 GameObject입니다.
그렇기 때문에 Player 의 메소드를 쓰려면 Player로 캐스팅해줘야만 합니다.
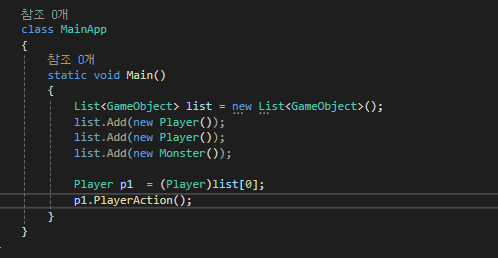
이런 식의 캐스팅을 사용할 수도 있지만
좀 더 나은 캐스팅 방법이 있는데,
바로 is와 as입니다.
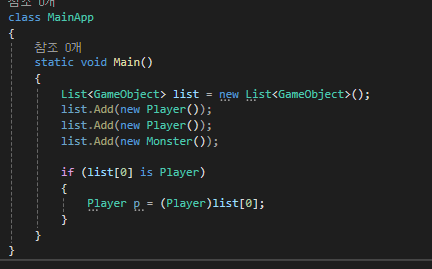
is의 경우
특정 클래스가 맞냐? 아니냐? 에 대해서 bool 값을 반환합니다.
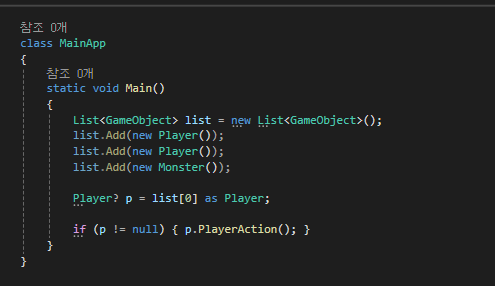
as는
C++ 의 dynamic_cast처럼 동작합니다.
변환이 불가하면 p에 null을 저장합니다.
단, as 연산자는 참조 형식에 대해서만 사용할 수 있으므로 값 형식의 객체는 기존의 형식 변환 연산자를 사용해야 합니다.
[다형성]
객체가 여러 형태를 가질 수 있도록 하는 것이 다형성입니다.
하위 클래스에서 부모 클래스의 함수를 재정의하는 것을 오버라이딩이라고 하는데
오버라이딩을 통해서 다형성을 구현할 수 있습니다.
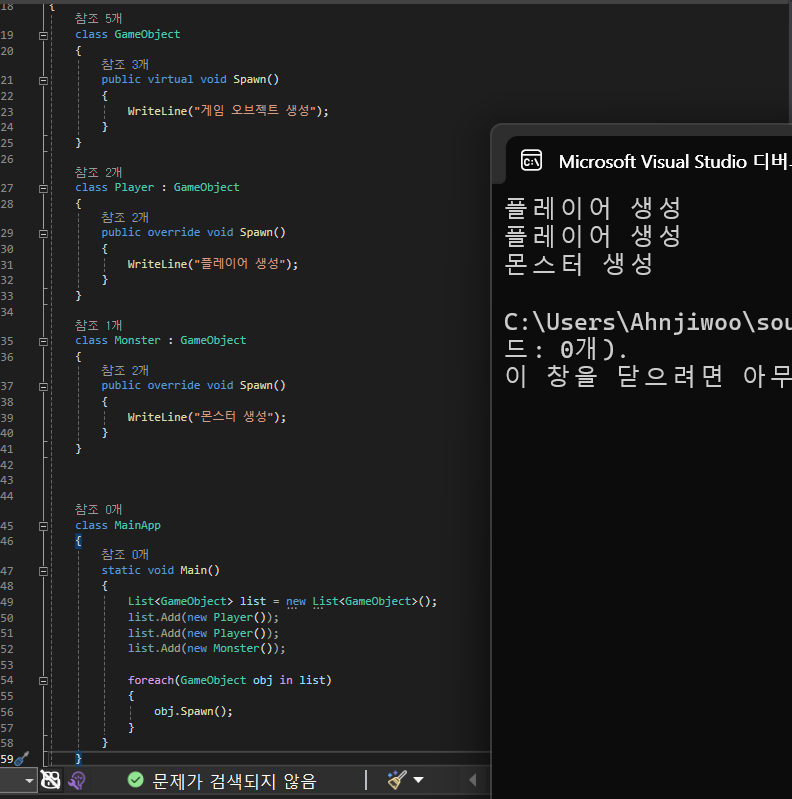
[메소드 숨기기]
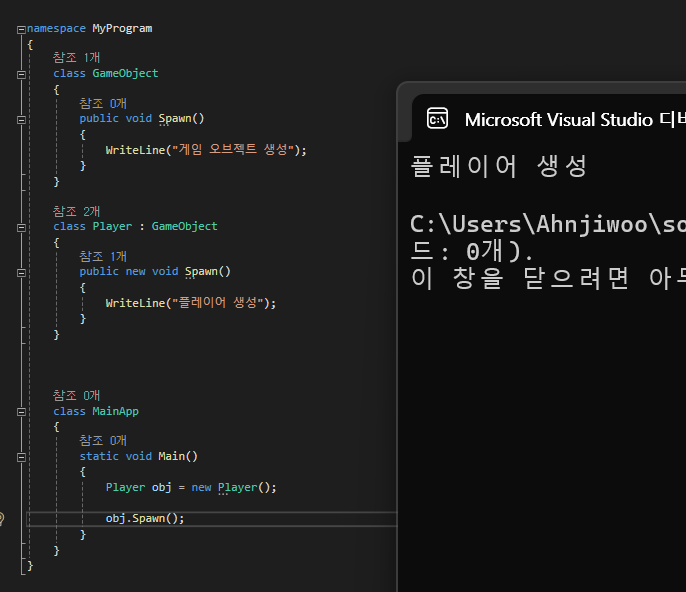
메시지 숨기기는 구현하려는 메소드와 동일한 이름의 함수가 부모에 있을 경우
해당 함수를 숨깁니다.
이러면 아치 오버라이딩이랑 비슷하게 동작합니다.
오버라이딩과 다른점은
Object 에 담긴 Player 객체라면 Player 버전의 Spawn을 호출하지 않고
Object의 Spawn를 호출한다는 것입니다.
즉, 메소드 숨기기 기법으로는 오버라이딩의 기능을 구현하기 힘들다라는 것을 기억해주시면 되겠습니다.
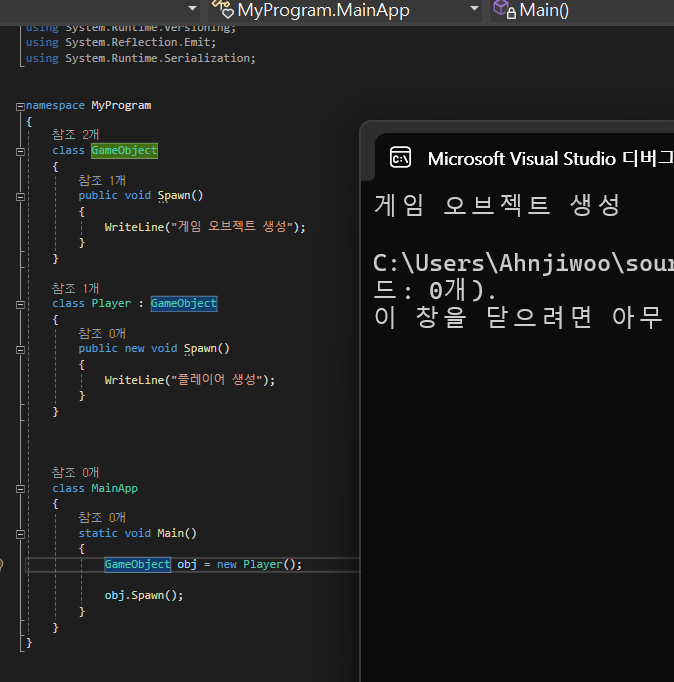
[오버라이딩 봉인하기]
sealed 키워드를 통해서 봉인할 수 있습니다.
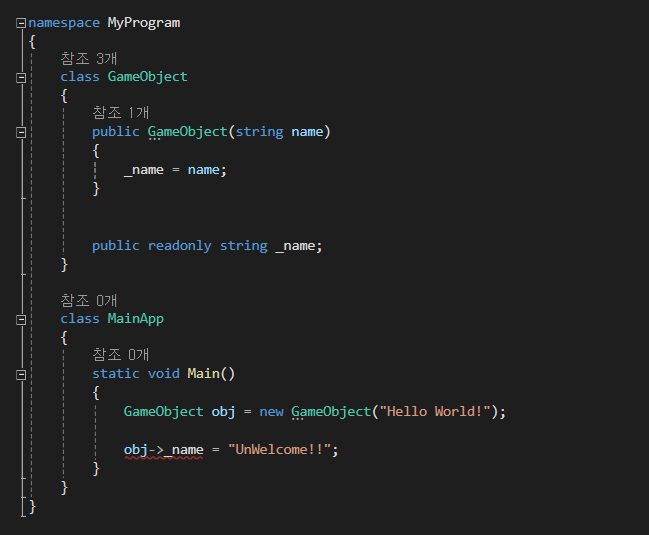
[읽기 전용 필드]
상수는 const 키워드를 통해서 선언합니다.
컴파일러는 런타임 중에는 절대 그 값을 바꿀 수 없습니다.
언제든지 바뀔 수 있는 값은 변수이죠
읽기 전용 필드는 상수와 변수 그 중간에 있습니다.
읽기 전용 필드는 읽기만 가능한 필드고, 생성자 안에서 한 번 값을 지정함녀, 그 후로는 값을 변경할 수 없습니다.
즉, 생성자 안에서만 초기화할 수 있는 것을 읽기전용 필드라고 부릅니다.
어떻게 보면 컴파일 시간에 바인딩 되는건 아니지만
마치 상수처럼 쓰기라는 행동이 아예 막혀있는 것을 볼 수 있죠.
(마치 C++에서 템플릿 상수를 사용하는 것과 비슷한 느낌이 듭니다.)
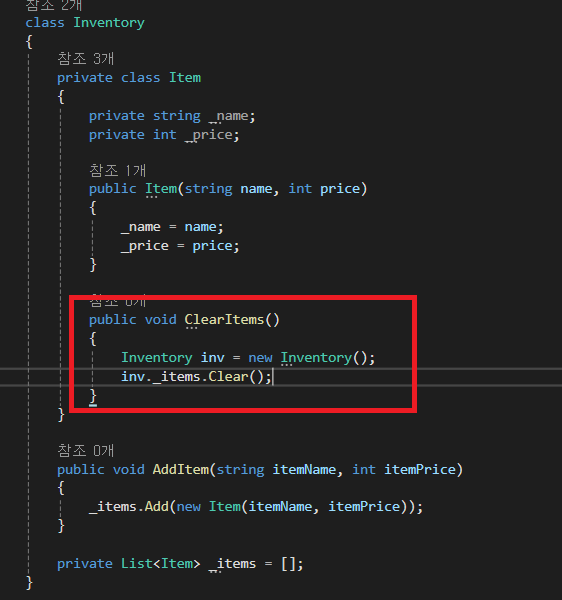
[중첩 클래스]
중첩 클래스는 클래스 안에 선언되어 있는 클래스를 말합니다.
클래스 안에 클래스를 선언하는 것이 전부일 정도로 문법은 매우 간단합니다.
다른 점이 있다면, 자신이 소속된 클래스의 멤버에 자유롭게 접근할 수 있다는 사실입니다.
private 멤버에도 자유롭게 접근할 수 있죠.
보통
- 클래스 외부에 공개하고 싶지 않은 형식을 만들고자 할 때
- 현재 클래스의 일부분처럼 표현할 수 있는 클래스를 만들고자 할 떄
즉, 클래스 내부에서만 사용할 형식을 다룰 때
이러한 중첩 클래스를 사용합니다.
[분할 클래스]
분할 클래스는 특별한 기능을 하는 것은 아니고,
클래스의 구현이 길어질 경우 여러 파일에 나눠서 구현할 수 있게 하는 것 입니다.
다음과 같이 partial 키워드를 사용해서 작성합니다.
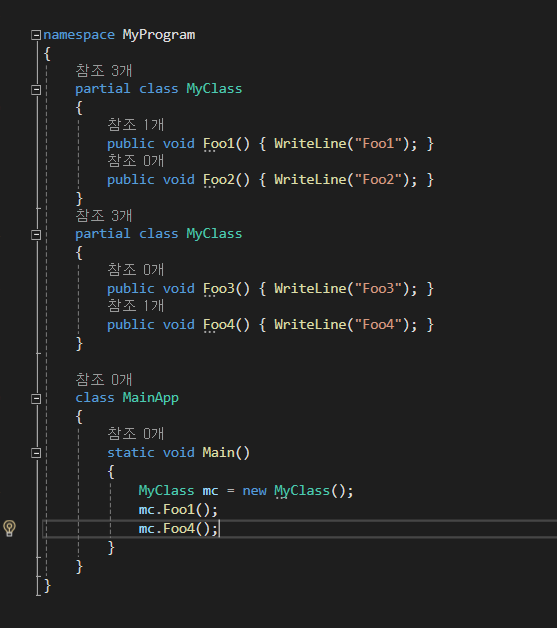
단, 클래스의 이름은 동이랳야 합니다.
분할을 하여도 하나의 클래스인 것처럼 사용할 수 있습니다.
[확장 메소드]
확장 메소드는 기존 클래스의 기능을 확장한느 기법입니다.
기반 클래스를 물려받아 파생 클래스를 만든 뒤 여기에 필드나 메소드를 추가하는 상속과는 다른 것이고,
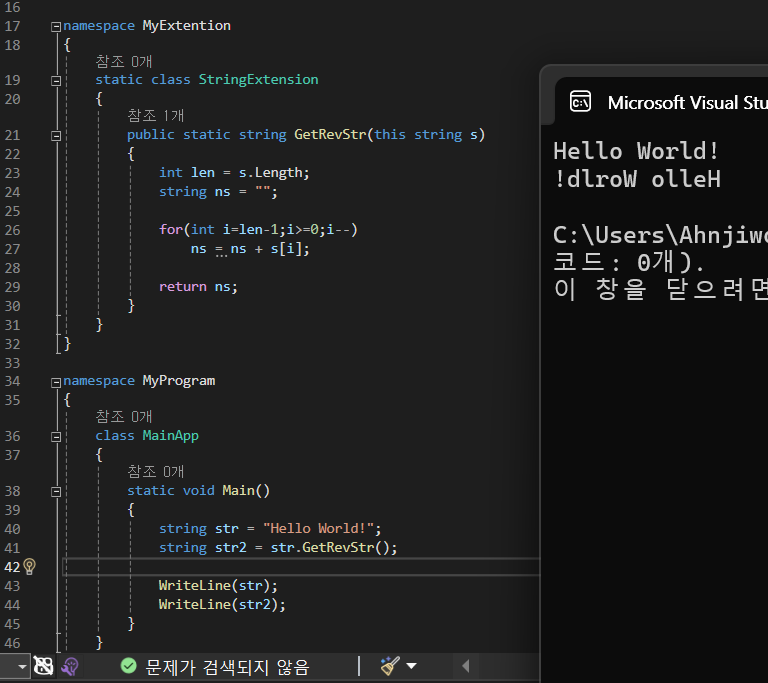
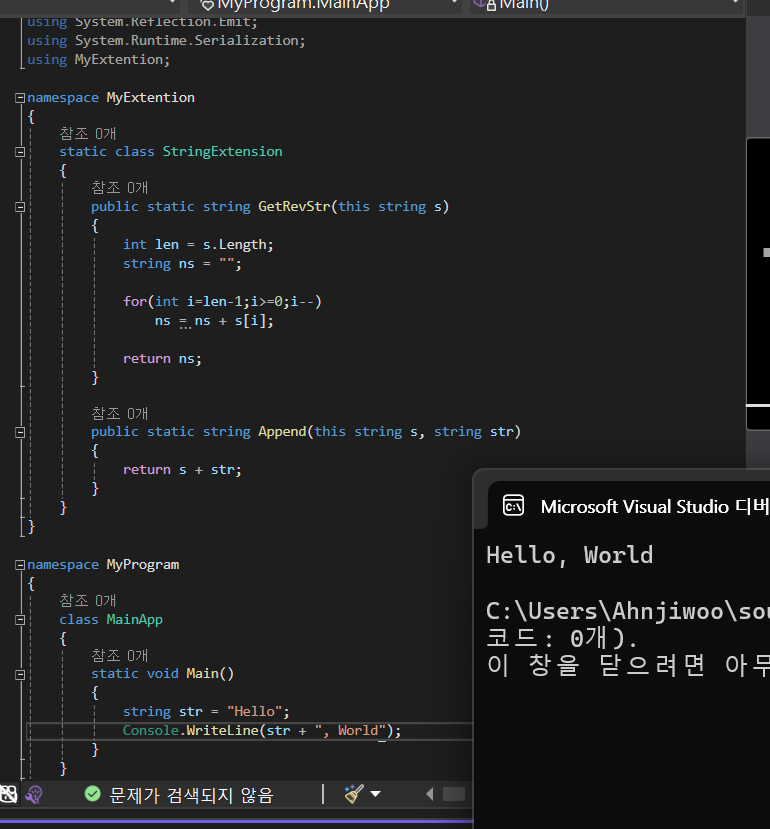
string 클래스에 문자열 뒤집기 기능을 추가하거나, int 형식에 제곱 연산 기능을 넣는 등의 확장을 구현합니다.
확장 메소드를 선언하는 방법은 다음과 같습니다.
메소드를 선언하되, static 한정자로 수식해야 합니다.
그리고 메소드의 첫 번째 매개변수는 반드시 this 키워드와 함께 확장하려는 클래스의 인스턴스여야 합니다.
그 뒤에 따라오는 매개변수 목록이 실제로 확장 메소드를 호출할 떄 입력된는 매개변수입니다.
메소드는 클래스 없이 선언될 수 없죠? 따라서 클래스를 하나 선언하고 그 안에 확장 메소드를 선언합니다.
또, 확장 메소드는 반드시 '정적 클래스' 안에 정의돼야 합니다.
[구조체]
구조체는 struct 으로 선언하며 class와 매우 유사합니다.
class가 객체 구현을 위한 틀로 사용되는 반면
struct은 대부분 데이터 형식을 담는 자료구조로 많이 활용됩니다.
차이점은 다음과 같습니다.
| 클래스 | 구조체 | |
| 데이터 저장 형식 | 힙에 할당 | 스택에 할당 |
| 복사 | 얕은 복사 | 깊은 복사 |
| 인스턴스 생성 | new 연산자 | 선언만으로도 생성 |
| 생성자 | 매개변수 없는 생성자 사용 가능 | 매개변수 없는 생성자 사용 불가 |
| 상속 | 가능 | 불가능 |
구조체는 가비지 콜렉터에 휘둘리지 않는 점 때문에 성능 면에서 이점을 가진다.
구조체는 매개변수가 없는 생성자는 선언할 수 없다고 했는데, 구조체의 각 필드는 CLR이 기본값으로 초기화해주니까 걱정하지 않아도 됩니다.
기본적으로 구조체는 깊은 복사로 이루어지기 때문에 (에초에 힙 영역에 배치되지도 않지만..)
동시성 문제는 신경쓰지 않아도 됩니다.
객체는 속성과 기능으로 이루어지고
속성은 상태
기능은 행위
라고도 합니다.
또, 상태의 변화를 허용하는 객체를 변경가능(Mutable) 객체라고 하고
상태의 변화를 불허용하는 객체는 변경불가능(Immutable) 객체 라고 합니다.
Immutable 객체를 사용하면, 멀티스레드 간에 동기화를 할 필요가 없기에 프록르매 성능 향상이 가능하고, 무엇보다 버그로 인한 데이터의 오염을 막을 수 있습니다.
구조체는 모든 필드와 프로퍼티의 값을 수정할 수 없는, 즉 변경불간으 구조체로 선언할 수 있습니다.
(이에 반해 클래스는 Immutable 하게 선언할 수 없습니다.)
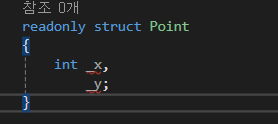
이때, 사용하는 키워드가 readonly 입니다.
단, readonly 구조체의 데이터 필드는 반드시 readonly로 선언되어야 합니다.
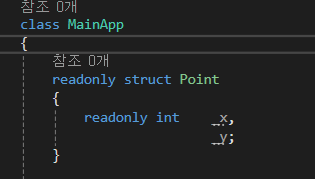
물론 생성자에서만 초기화가 가능하고, 추가적인 수정은 불가합니다.
[readonly 메서드]
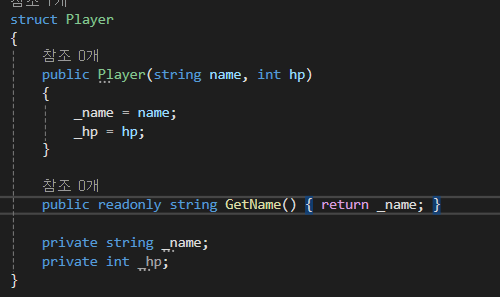
메소드에게 상태를 바꾸지 않도록 강제하는 메소드 키워드
구조체에서만 사용할 수 있습니다.
[튜플]
튜플도 여러 필드를 담을 수 있는 구조체입니다.
하지만 앞서 살펴봤던 구조체와는 달리 튜플은 형식 이름이 없습니다.
그래서 튜플은 응용 프로그램 전체에서 사용할 형식을 선언할 때가 아닌, 즉석에서 사용할 복합 데이터 형식을 선언할 때 적합합니다.
튜플은 구조체 기반이므로 값 형식입니다.
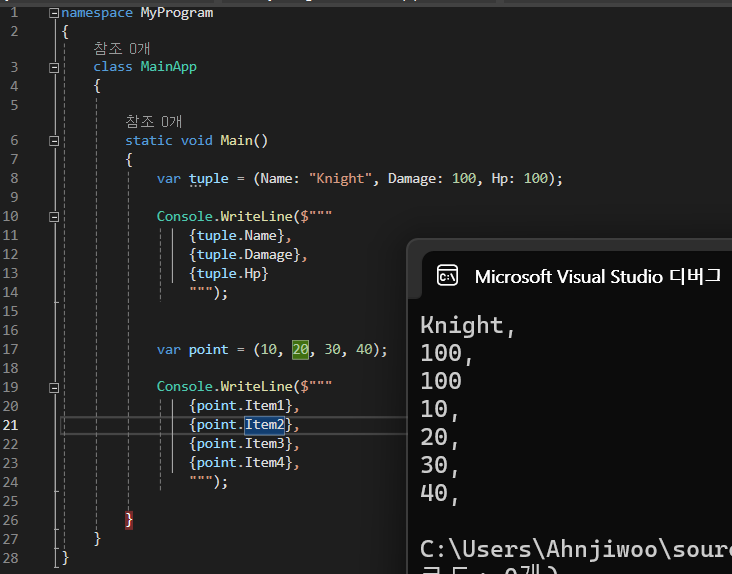
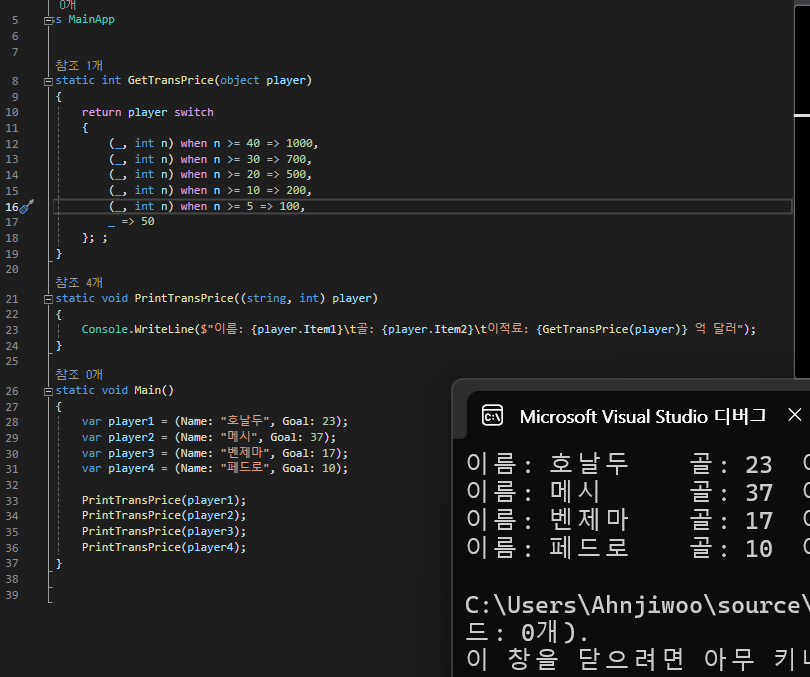
예제
필드 명을 명시할 수도 있고 (명명된 튜플)
필드 명을 명시하지 않으면 Item 으로 구분합니다. (명명되지 않은 튜플)
[튜플의 분해]
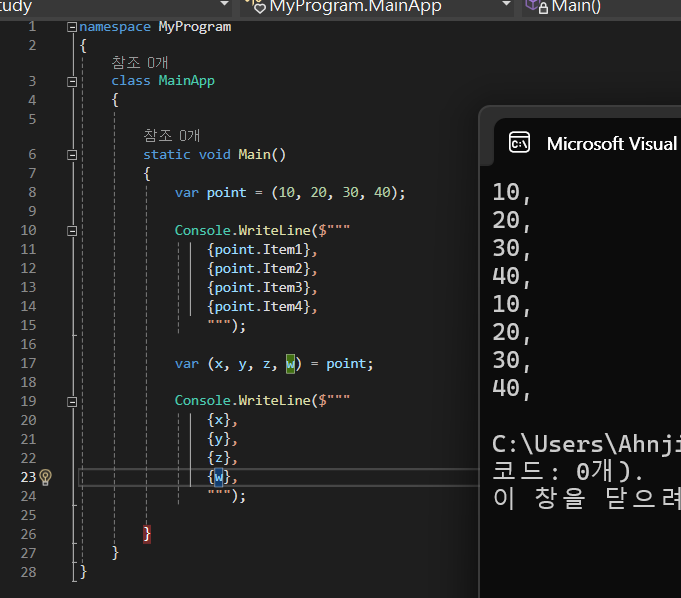
선언의 역으로 분해할 수도 있다.
튜플의 분해를 이용하면 다음과 같이 여러 변수를 단번에 생성하고 초기화할 수 있습니다.
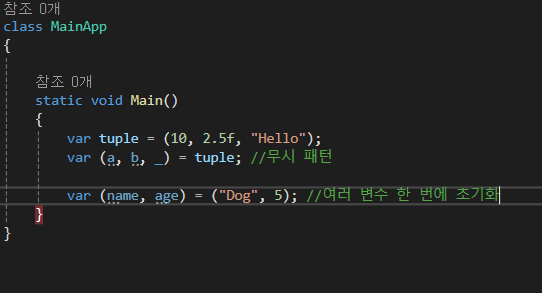
튜블이 분해가 가능한 이유는 분해자를 구현하고 있기 떄문인데요.
분해자를 구현하고 있는 객체를 분해한 결과를 switch 문지나 switch 식의 분기 조건에 활용할 수 있습니다.
이것을 위치 패턴 매칭이라고 합니다.
식별자나 데이터 형식이 아닌 분해된 요소의 위치에 따라 값이 일치하는지를 판단하는 것이죠.
'언어 > C#' 카테고리의 다른 글
| [C#] ref 키워드와 out 키워드 (0) | 2024.05.04 |
|---|---|
| [C#] C++에 비해서 강력해진 switch문! (0) | 2024.05.04 |
| [C#] C#에서 볼 수 있었던 생소한 연산자들 (0) | 2024.05.01 |
| [C#] 데이터 형식 (0) | 2024.04.29 |
| [C#] C# 스터디 시작합니다. (0) | 2024.04.27 |



