1. 신장 트리
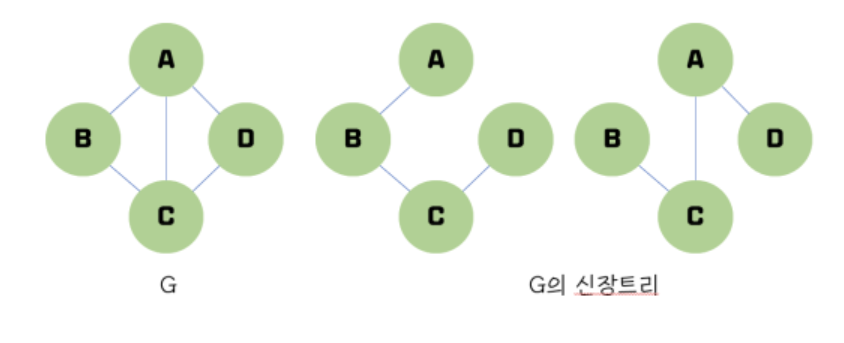
신장 트리(Spanning tree)란 그래프내의 모든 정점을 포함하는 부분 그래프(혹은 트리)이다.
신장 트리는 특수한 형태로 모든 정점들이 연결되어 있어야 하고 사이클을 포함하면 안된다.
따라서 신장 트리는 그래프에 있는 n개의 정점을 정확히 (n-1) 개의 간선으로 연결하게 된다.
하나의 그래프에는 많은 신장 트리가 존재할 수 있다.
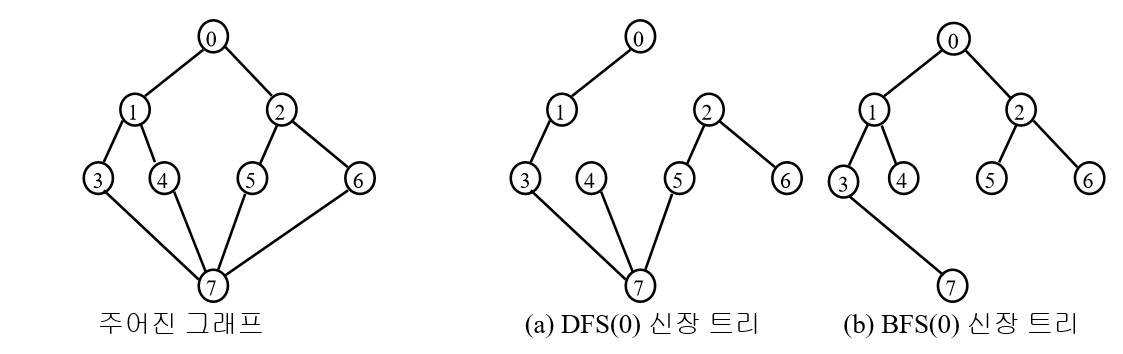
신장 트리의 경우 BFS, DFS 를 사용하면 도중에 사용된 간선을 모아 만들 수 있다.
신장 트리는 그래프의 최소 연결 부분 그래프가 된다.
여기서 최소의 의미는 간선의 수가 가장 적다는 의미이다.
n개의 정점을 가지는 그래프는 최소한 (n-1)개의 간선을 가져야 하며, (n-1)개의 간선으로 연결되어 있으면 필연적으로 트리 형태가 되고 이것은 바로 신장 트리가 된다.
신장 트리는 어디에 사용될까?
신장 트리는 통신 네트워크 구축에 많이 사용된다.
예를 들어 n개의 위치를 연결하는 통신 네트워크를 최소의 링크를 이용하여 구축하고자 할 경우, 최소 링크수는 (n-1)이 되고 따라서 신장 트리들이 가능한 대안이 된다.
예를 들어, 회사 내의 모든 전화기를 가장 적은 수의 케이블을 사용하여 연결하고자 한다면 신장 트리를 구함으로써 해결할 수 있다.


2. 최소 신장 트리
통신망, 도로망, 유통망 등은 간선에 가중치가 부여된 가중치 그래프로 표현될 수 있다.
가중치는 길이, 구축 비용, 전송 시간 등을 나타낸다. 이러한 도로망, 통신망, 유통망을 가장 적은 비용으로 구축하고자 한다면, 가중치 그래프에 있는 모든 정점들을 가장 적은 수의 간선과 비용으로 연결하는 최소 비용 신장 트리(이하 MST, Minimum Spanning Tree)가 필요하게 된다.
MST는 신장 트리 중에서 사용된 가선들의 가중치 합이 최소인 신장 트리를 말한다.

MST의 응용의 예를 들면 다음과 같다.
- 도로 건설: 도시들을 모두 연결하면서 도로의 길이가 최소가 되도록 하는 문제
- 전기 회로: 단자들을 모두 연결하면서 전선의 길이가 가장 최소가 되도록 하는 문제
- 통신: 전화선의 길이가 최소가 되도록 전화 케이블 망을 구성하는 문제
- 배관: 파이프를 모두 연결하면서 파이프의 총 길이가 최소가 되도록 연결하는 문제
최소 비용 신장 트리를 구하는 방법으로는 Kruskal(이하 크루스칼) 과 Prim(이하 프림)이 제안한 알고리즘이 대표적으로 사용되고 있으며, 이 알고리즘들은 최소 비용 신장 트리가 간선의 가중치의 합이 최소이어야 하고, 반드시 (n-1)개의 간선만 사용해야 하며, 사이클이 포함되어서는 안 된다는 조건들을 적절히 이용하고 있다.
(1) 크루스칼의 MST 알고리즘
[1] 개요
크루스칼의 알고리즘을 그리디 알고리즘을 이용하고 있다.
그리디 알고리즘이란 순간순간 가장 좋은 선택지를 골라서 최종적인 해답에 도달하는 방법이다.
실제로 상당히 좋은 알고리즘을 만들어 내는 알고리즘 설계 기법이다.
(참고자료)
https://powerclabman.tistory.com/17
[ C++/알고리즘] 그리디 알고리즘 (Greedy Algorithm)
📕 개요그리디 알고리즘은 '욕심쟁이 알고리즘'이라는 별칭을 가지고 있습니다. 이는 '지금 이 순간 최적의 답을 선택하여, 전체 문제를 해결하자!'라는 아이디어로부터 출발합니다. 간단한 예
powerclabman.tistory.com
그리디 알고리즘에서 순간의 선택은 그 당시에는 자명한 최적해이지만, 최적이라고 생각했던 지역적인 해답들을 모아서 최종적인 해답을 만들었다고 해서, 그 해답이 반드시 전역적으로 최적이라는 보장은 없다.
따라서 탐욕적인 방법은 항상 최적의 해답이 주는지는 몇 가지 검증이 필요하다.
다행히 크루스칼 MST 알고리즘은 최적의 해답을 주는 것으로 증명되어 있다.
크루스칼 알고리즘은 최소 비용 신장 트리가 최소 비용의 간선으로 구성됨과 동시에 사이클을 포함하지 않는다는 조건에 근거하여, 각 단계에서 사이클을 이루지 않는 최소 비용 간선을 선택한다. 이러한 과정을 반복함으로써 가중치 그래프의 모든 정점을 최소 비용으로 연결하는 최적 해답을 구할 수 있다.
알고리즘의 논리 과정은 다음과 같이 이루어진다.
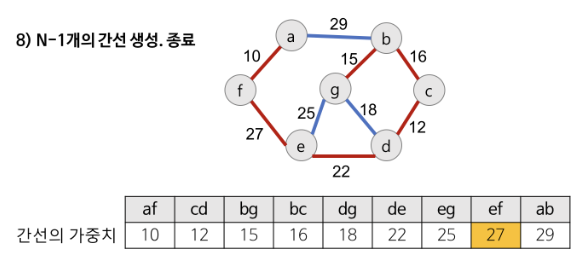
1) 그래프의 간선들을 가중치의 오름차순으로 정렬한다.
2) 정렬된 간선들의 리스크에서 가장 작은 가중치 간선부터 MST 집합에 추가한다.
3) 단, 추가할 간선이 사이클을 형성한다면 해당 간선은 집합에서 제외한다.

크루스칼 알고리즘의 핵심은 추가할 간선이 사이클을 형성하는지 체크하는 것이다.
새로운 간선이 이미 다른 경로에 의하여 연결되어 있는 정점들을 연결할 때 사이클이 형성된다.

만약 위와 같은 2개의 그래프 집합이 존재한다고 가정했을 때,
정점 5와 3은 서로 다른 그래프 집합에 속해있기 때문에 간선으로 연결한다 하더라도 사이클이 발생하지 않는다.
그러나 1, 5 처럼 같은 그래프 집합에 속해있을 경우 이 둘을 연결하면 사이클이 발생하게 된다.
즉, 사이클 검사를 위해서는 지금 추가하고자 하는 간선의 양끝 정점이 같이 집합에 속해 있는지를 검사하여야 한다.
이 검사를 위한 알고리즘은 '서로소 집합(Disjoint-Set) 알고리즘' 이라고 불리는 union-find 알고리즘을 사용하여 검사한다.
[2] Union-Find 연산
union-find 연산은 크루스칼 알고리즘에서만 사용되는 것은 아니고 일반적으로 널리 사용된다.
union(x, y) 연산은 원소 x와 y가 속해있는 집합을 입력으로 받아 2가의 집합의 합집합을 만든다.
find(x) 연산은 원소 x가 속해있는 집합을 반환한다.
예를 들어 S = {1, 2, 3, 4, 5, 6} 의 집합을 가정하자.
처음에는 집합의 원소를 하나씩 분리하여 독자적인 집합으로 만든다.
{1}, {2}, {3}, {4}, {5}, {6}
여기에 union(1,4) 와 union(5,2) 를 하면 다음과 같은 집합으로 변화된다.
{1, 4}, {5, 2}, {3}, {6}
또한 이어서 union(4, 5) 와 union(3, 6) 을 한다면 다음과 같은 결과를 얻을 수 있다.
{1, 4, 5, 2}, {3, 6}
[3] Union-find 구현
집합을 구현하는 데는 여러 가지 방법이 있을 수 있다.
비트 벡터, 배열, 연결 리스트를 이용하여 구현될 수 있다.
그러나 가장 효율적인 방법은 트리 형태를 사용하는 것이다.
우리는 부모 노드만 알면 되므로 "부모 포인터 표현"을 사용한다.
"부모 포인터 표현"이란 각 노드에 대해 그 노드의 부모에 대한 포인터만 저장하는 것이다.
쉽게 말해서, 1차원 배열을 통해서 특정 노드의 값은 자신의 부모 노드의 값을 갖도록 하는 것이다.
이는 "두 노드가 같은 트리에 있습니까?"라는 질문에 대답하는데 충분한 데이터가 된다.

예를 들어 위와 같은 노드들이 있다고 하자, 처음에는 전부 분리되어 있고
부모가 존재하지 않으므로 -1 이 배열에 저장되어 있다.
여기서 union(0, 1) 가 실행되었다면 다음과 같이 변경된다.

여기서 union(3, 4)와 union(1, 5)를 차례로 수행해보겠다.

여기서 union(2, 5) 를 수행해보겠다.
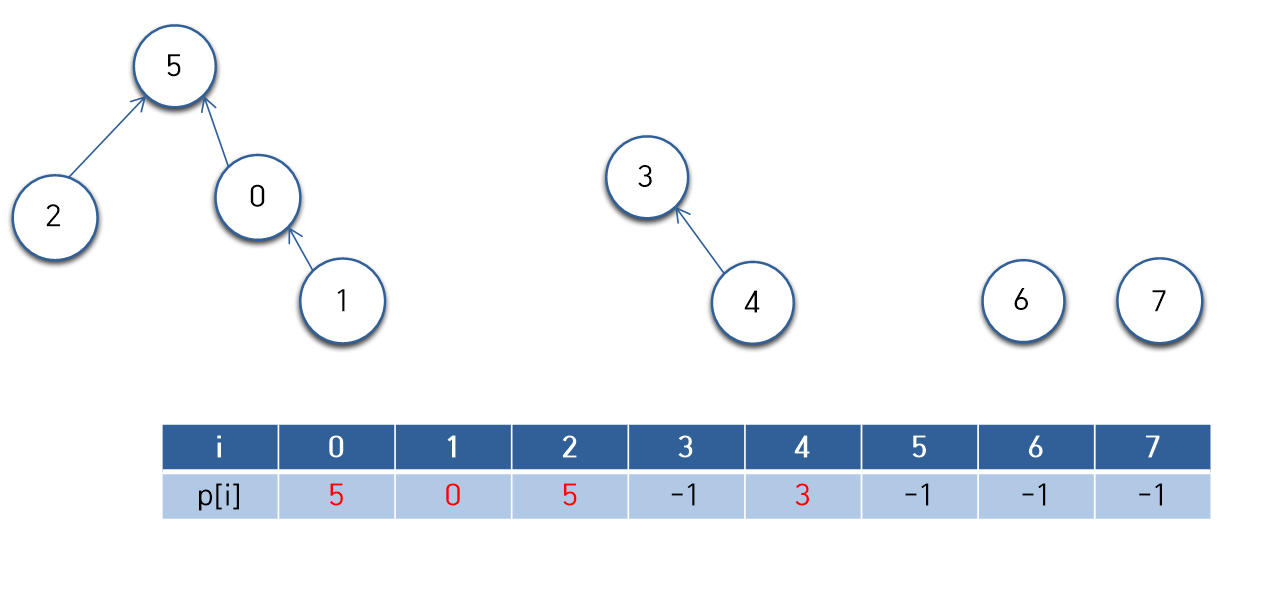
find는 앞서 말했듯 해당 원소가 포함된 집합을 반환한다고 하였다.
자신 인덱스의 값을 읽으면 부모 노드를 찾을 수 있고
인덱스의 값이 -1이 될 때 까지 계속해서 거슬러 올라가면 결국 같은 집합에 속한 노드는 최종적으로 같은 노드를 가리키게 된다.
즉, find(2)와 find(0), find(1), find(5) 는 최종적으로 모두 같은 값을 반환한다.
이런 방식으로 find 연산을 통해 서로 다른 두 정점이 같은 집합에 속해있는지 다른 집합에 속해있는지 판단할 수 있다.
즉, find 연산을 이용하면 크루스칼 알고리즘에서 어떤 두 정점을 연결했을때 사이클이 생기는지 판단하는데 알 수 있다는 것이다.
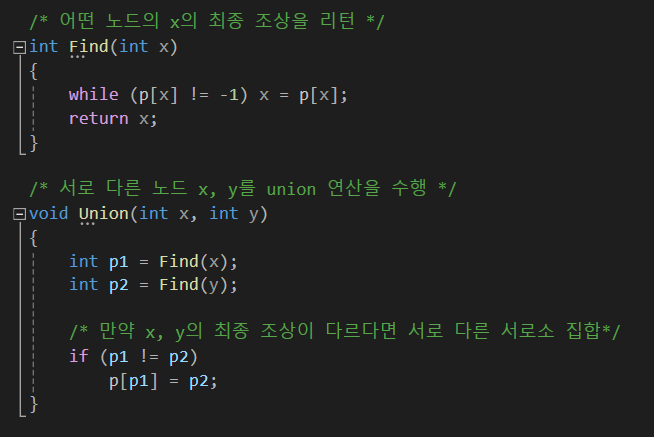
다음은 C++ 코드로 Union-Find 연산을 구현한 것이다.

[4] 크루스칼 MST 알고리즘 구현
위의 Union 연산과 find 연산을 이용하여 Kruskal의 알고리즘을 구현해보면 다음과 같다.
참고로 정렬 알고리즘은 라이브러리를 사용하였다.

#include <iostream>
#include <vector>
#include <cassert>
#include <algorithm>
using namespace std;
/* 간선 정보 */
struct Edge
{
int start,
end,
cost;
};
vector<Edge> adjacent; /* 간선 집합 */
vector<int> parent; /* Union-Find 연산에서 사용할 부모 트리 */
int rst; /* MST의 가중치를 저장하는 변수 */
int Find(int x)
{
while (parent[x] != -1) x = parent[x];
return x;
}
bool Union(int x, int y)
{
int v1 = Find(x);
int v2 = Find(y);
if (v1 == v2) return false; /*x, y는 같은 집합*/
else
{
/* Union 연산 가능 */
parent[v1] = v2;
return true;
}
}
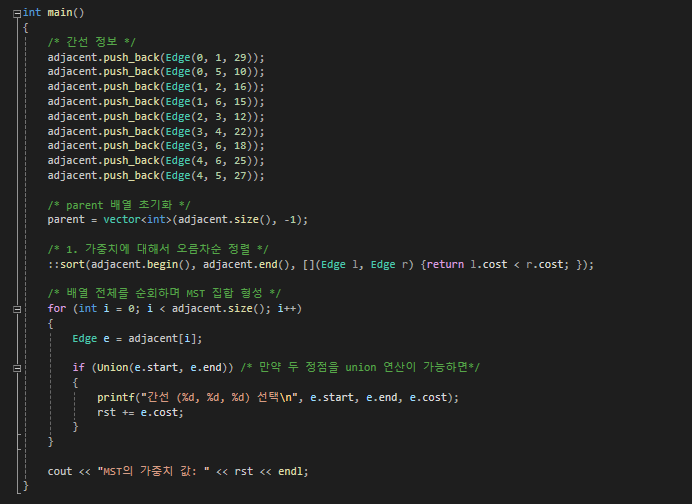
int main()
{
/* 간선 정보 */
adjacent.push_back(Edge(0, 1, 29));
adjacent.push_back(Edge(0, 5, 10));
adjacent.push_back(Edge(1, 2, 16));
adjacent.push_back(Edge(1, 6, 15));
adjacent.push_back(Edge(2, 3, 12));
adjacent.push_back(Edge(3, 4, 22));
adjacent.push_back(Edge(3, 6, 18));
adjacent.push_back(Edge(4, 6, 25));
adjacent.push_back(Edge(4, 5, 27));
/* parent 배열 초기화 */
parent = vector<int>(adjacent.size(), -1);
/* 1. 가중치에 대해서 오름차순 정렬 */
::sort(adjacent.begin(), adjacent.end(), [](Edge l, Edge r) {return l.cost < r.cost; });
/* 배열 전체를 순회하며 MST 집합 형성 */
for (int i = 0; i < adjacent.size(); i++)
{
Edge e = adjacent[i];
if (Union(e.start, e.end)) /* 만약 두 정점을 union 연산이 가능하면*/
{
printf("간선 (%d, %d, %d) 선택\n", e.start, e.end, e.cost);
rst += e.cost;
}
}
cout << "MST의 가중치 값: " << rst << endl;
}
[5] 크루스칼 알고리즘 분석
union-find 알고리즘을 이용하면 크루스칼 알고리즘의 시간 복잡도는 간선들을 정렬하는 시간에 좌우된다.
즉, 알고리즘의 시간 복잡도는 O(e log e) 이다.
여기서 e는 간선의 개수를 의미한다.
(2) Prim의 MST 알고리즘
Prim의 알고리즘은 시작 정점에서부터 출발하여 신장 트리 집합을 단계적으로 확장해나가는 방법이다. 시작 단계에서는 시작 정점만이 신장 트리 집합에 포함된다. Prim의 방법은 앞 단계에서 만들어진 신장 트리 집합에, 인접한 정점들 중에서 최저 간선으로 연결된 정점을 선택하여 트리를 확장한다.
이 과정은 트리가 n-1개의 간선을 가질 떄까지 계속된다.
크루스칼 알고리즘과 다른 점은 크루스칼 알고리즘의 경우 간선을 기준으로 MST를 구성하지만
프림의 경우에는 정점을 기준으로 MST를 구성한다는 차이점이 있다.
또, 크루스칼 알고리즘의 경우 무조건 최저 간선만을 선택하는 방법이었던데 반하여 Prim의 알고리즘은 이전 단계에서 만들어진 신장 트리를 확장하는 방식이다.

알고리즘의 논리 과정은 다음과 같다.
1) 시작 정점을 기준으로 주변 간선들의 가중치를 탐색한다.
2) 발견한 간선들중 가장 저렴한 간선을 선택한다.
단, 이미 발견한 정점은 방문하지 않는다.
3) 이를 반복한다.
[2] Prim MST 알고리즘 구현
우선 순위 큐가 하나 필요한데, 이는 효율적으로 가장 저렴한 간선을 선택하기 위해서이다.
물론 탐색으로 찾을 수 있지만, 우선 순위 큐를 활용하면 더욱 효율적으로 최소값을 찾을 수 있다.
우선 순위 큐는 가중치를 기준으로 최소 힙을 형성한다.
우선 순위 큐에서 가장 작은 가중치 값을 가지는 정점을 끄집어내어 이를 트리 집합에 추가한다.
더하여, 한 번 방문한 노드는 또 방문하면 안되므로 visitied 배열을 생성하여 방문 여부를 체크한다.
아래 코드는 인접 행렬을 통해서 Prim MST 알고리즘을 구현하였다.
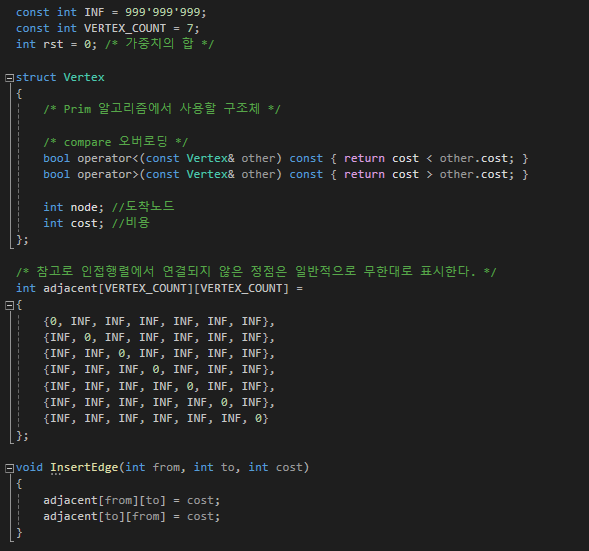


#include <iostream>
#include <vector>
#include <cassert>
#include <queue>
#include <algorithm>
using namespace std;
const int INF = 999'999'999;
const int VERTEX_COUNT = 7;
int rst = 0; /* 가중치의 합 */
struct Vertex
{
/* Prim 알고리즘에서 사용할 구조체 */
/* compare 오버로딩 */
bool operator<(const Vertex& other) const { return cost < other.cost; }
bool operator>(const Vertex& other) const { return cost > other.cost; }
int node; //도착노드
int cost; //비용
};
/* 참고로 인접행렬에서 연결되지 않은 정점은 일반적으로 무한대로 표시한다. */
int adjacent[VERTEX_COUNT][VERTEX_COUNT] =
{
{0, INF, INF, INF, INF, INF, INF},
{INF, 0, INF, INF, INF, INF, INF},
{INF, INF, 0, INF, INF, INF, INF},
{INF, INF, INF, 0, INF, INF, INF},
{INF, INF, INF, INF, 0, INF, INF},
{INF, INF, INF, INF, INF, 0, INF},
{INF, INF, INF, INF, INF, INF, 0}
};
void InsertEdge(int from, int to, int cost)
{
adjacent[from][to] = cost;
adjacent[to][from] = cost;
}
int main()
{
/* 간선 정보 */
InsertEdge(0, 1, 29);
InsertEdge(0, 5, 10);
InsertEdge(1, 2, 16);
InsertEdge(1, 6, 15);
InsertEdge(2, 3, 12);
InsertEdge(3, 4, 22);
InsertEdge(3, 6, 18);
InsertEdge(4, 6, 25);
InsertEdge(4, 5, 27);
/* 방문 배열과 우선순위 큐 */
vector<bool> visited(VERTEX_COUNT, false);
priority_queue < Vertex, vector<Vertex>, greater<Vertex>> pq;
/* 시작점은 0 */
pq.push(Vertex{ 0,0 });
while (!pq.empty())
{
Vertex v = pq.top();
pq.pop();
if (visited[v.node] == true) continue;
visited[v.node] = true;
rst += v.cost; // 최종값 연산
printf("정점 %d 추가, 가중치: %d\n", v.node, v.cost);
for (int i = 0; i < VERTEX_COUNT; i++)
{
/* 이미 방문한 노드이거나 연결되어 있지 않으면 스킵 */
if (visited[i] == true || adjacent[v.node][i] == INF) continue;
pq.push(Vertex{ i, adjacent[v.node][i] });
}
}
cout << "가중치 합: " << rst << endl;
}
[3] Prim의 알고리즘의 분석
Prim의 알고리즘의 시간 복잡도는 인접행렬을 사용할 경우 O(n²) 의 복잡도를 가지고, 인접리스트의 경우
O(Elog V)의 복잡도를 가진다. (E: 간선의 수, V: 정점의 수)
3) 언제 Prim 알고리즘을 사용하고 언제 Kruskal 알고리즘을 사용하는 것이 좋을까?
크루스칼 알고리즘의 복잡도는 O(ElogE) 이므로 희소 그래프에서 유리하다.
프림 알고리즘의 복잡도는 O(n^2) 이므로 밀집 그래프에서 유리하다.
3. 최단 경로
최단 경로(Shortest Path) 문제는 가중치 그래프에서 정점 i와 정점 j를 연결하는 경로 중에서 간선들의 가중치 합이 최소가 되는 경로는 찾는 문제이다. 간선의 가중치는 비용, 거리, 시간 등을 나타낸다.

지도를 나타내느 그래프에서 정점은 각 도시들을 나타내고 가중치는 한 도시에서 다른 도시로 가는 거리를 의미한다.
여기서의 문제는 도시 u에서 도시 v로 가는 거리 중에서 전체 길이가 최소가 되는 경로를 찾는 것이다.

예를 들어 위 그림의 그래프를 생각하자
가중치가 인접행렬에 저장되어 있고, 만약 정점 u, v 사이의 연결이 없다면 무한대 값을 저장하고 있다.
어떤 식으로 최단 경로를 발견할 것인가?
대표적인 알고리즘은
Dijkstra 알고리즘 (이하 다익스트라 알고리즘)
Floyd-Warshall 알고리즘 (이하 플로이드-워셜 알고리즘)
이렇게 2가지 존재한다. (Bellman-Ford 알고리즘도 유용하게 쓰인다.)
다익스트라 알고리즘은 하나의 시작 정점에서 다른 정점까지의 최단 경로를 구한다.
플로이드-워셜 알고리즘은 모든 정점에서 다른 모든 정점까지의 최단 경로를 구한다.
1) 다익스트라의 최단 경로 알고리즘

다익스트라의 최단 경로 알고리즘은 시작 정점 v 로 부터 다른 모든 정점까지의 최단 거리를 찾는 알고리즘이다.
먼저 시작 정점 v 부터 다른 모든 정점까지의 최단 거리를 저장하는 1차원 배열 distance가 필요하다.
다익스트라 알고리즘은 최초 시작 정점 v부터 시작하여 최단 경로를 탐색해 나가며 그 결과들을 distance 배열에 업데이트 해나가는 방식으로 동작하며, 최종적으로 distance 배열에는 시작 정점 v 부터 다른 정점까지의 자명한 최소 경로 길이만이 저장된다.
특정 시점에서의 시작 정점 v에서 다른 정점까지의 최단경로를 저장하는 1차원 배열을 distance
가중치 그래프의 가중치 값을 저장한 2차원 인접 행렬을 adjacent
방문한 노드를 기록하는 1차원 배열을 visited 라고 하겠다.
최초에는 distance 배열의 시작 정점 v를 제외한 모든 값은 INF로 초기화 된다.
distance[v] = 0 이다.
그리고 visited 또한 시작 정점 v를 제외한 모든 값은 false(혹은 0)으로 초기화 된다.
visited[v] = true (혹은 1) 이다.
다익스트라 알고리즘의 논리구조는 프림 알고리즘의 논리구조와 매우 유사하다.
1. 시작 정점에서 출발하여 안접한 경로의 가중치를 탐색한다.
2. 현재 노드에서 발견한 노드 w로 가는 비용은 distance[v] + adjacent[v][w]이다.
3. distance[w] = min(distance[w], distance[v] + adjacent[v][w] 이다.
4. 아직 방문하지 않은 노드 중 distance 값이 가장 작은 노드를 방문한다.
5. 모든 정점을 방문할 떄까지 반복한다.
아직 이 과정이 이해가 가지 않을 수도 있으니, 천천히 다시 설명해보겠다.
[2] 다익스트라 알고리즘 보충설명
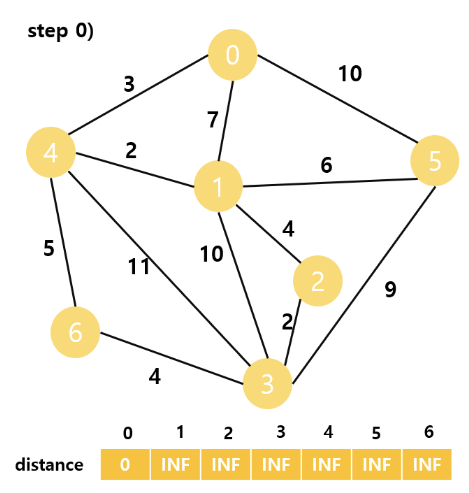
최초에는 distance 배열의 시작 정점 인덱스를 제외한 모든 값이 INF로 초기화되어있다.

시작 정점을 방문하고
visisted[0] = true 로 체크한다.
그리고 0과 인접한 정점은 1, 4, 5 이다.
그러므로 distance 배열을 업데이트 해준다.
distance[1] = min(INF, 0 + 7) = 7
distance[4] = min(INF, 0 + 3) = 3
distance[5] = min(INF, 0 + 5) = 10
이다.

현재 방문하지 않은 노드 중 distance 값이 가장 작은 노드는
노드 4이다.
이 떄, 노드 4로 가는 최소 경로 비용은 3으로 자명해진다.
그리고 노드 4 기준으로 인접 노드들을 탐색하고 distance 배열을 업데이트 한다.
distance[1] = min(7, 3 + 2) = 5
distance[3] = min(INF, 3 + 11) = 14
distance[6] = min(INF, 3 + 5) = 8

다음은 방문하지 않은 노드중 distance 값이 가장 작은 값을 가지는
노드 1을 방문한다.
이 이후는 직접 해보는 것을 권장한다.
[3] 다익스트라 알고리즘 구현
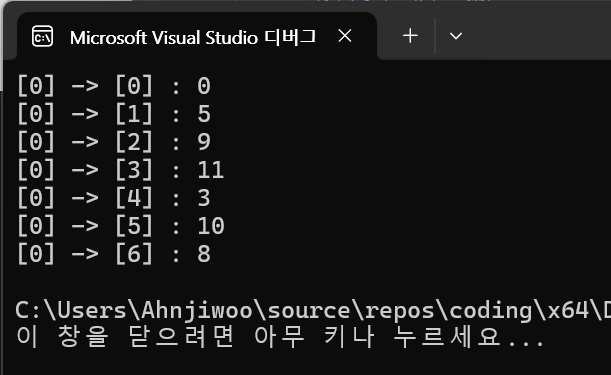
시작 정점을 0번으로 설정하여 다익스트라 알고리즘을 수행하였다.
그래프의 구성은 예시로 사용했던 그래프와 동일하게 구성하였다.
알고리즘 수행 결과 배열 distance에는 0번 정점으로ㅂ터 다른 모든 정점으로의 최단 경로 거리가 저장된다.


#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
const int INF = 999'999'999;
const int VERTEX_COUNT = 7;
int adjacent[VERTEX_COUNT][VERTEX_COUNT] = { 0, };
void InsertEdge(int from, int to, int cost)
{
adjacent[from][to] = cost;
adjacent[to][from] = cost;
}
int main()
{
/* 그래프 초기화 */
for (int i = 0; i < VERTEX_COUNT; i++)
for (int j = 0; j < VERTEX_COUNT; j++)
adjacent[i][j] = INF;
/* 정점 연결 */
{
for (int i = 0; i < VERTEX_COUNT; i++)
InsertEdge(i, i, 0);
InsertEdge(0, 1, 7);
InsertEdge(0, 4, 3);
InsertEdge(0, 5, 10);
InsertEdge(1, 4, 2);
InsertEdge(1, 5, 6);
InsertEdge(1, 2, 4);
InsertEdge(1, 3, 10);
InsertEdge(2, 3, 2);
InsertEdge(3, 4, 11);
InsertEdge(3, 5, 9);
InsertEdge(3, 6, 4);
InsertEdge(4, 6, 5);
}
/* visited 배열, distance 배열 */
bool visited[VERTEX_COUNT];
int distance[VERTEX_COUNT];
::fill(visited, visited + VERTEX_COUNT, false);
::fill(distance, distance + VERTEX_COUNT, INF);
distance[0] = 0;
while (true)
{
/* distance에서 최소값을 가짐과 동시에, 방문하지 않은 노드 선택 */
int minNode = -1;
int minCost = INF;
for (int i = 0; i < VERTEX_COUNT; i++)
{
if (visited[i] == true) continue; // 방문한 노드는 스킵
/* 현재 찾은 노드보다 더 작은 값을 발견시 업데이트 */
if (minCost > distance[i])
{
minCost = distance[i];
minNode = i;
}
}
/* 탈출조건, 만약 minNode == -1, 모든 노드를 다 방문했으므로 종료 */
if (minNode == -1)
break;
visited[minNode] = true;
/* 연결된 간선의 가중치를 탐색 */
for (int i = 0; i < VERTEX_COUNT; i++)
{
/* 연결되어 있지 않거나 방문한 노드는 제외 */
if (adjacent[minNode][i] == INF || visited[i] == true)
continue;
// distance 값을 업데이트
distance[i] = min(distance[i], minCost + adjacent[minNode][i]);
}
}
/* distance 출력 */
for (int i = 0; i < VERTEX_COUNT; i++)
printf("[0] -> [%d] : %d\n", i, distance[i]);
}
[4] 다익스트라 알고리즘 최적화
위 다익스트라 알고리즘의 경우
최소값의 distance Node 를 찾는데 O(N), 인접 노드를 탐색하는데 O(N)의 시간이 소모되기에
총 O(N²) 의 시간 복잡도가 소모된다고 말할 수 있다.
그러나 최소값을 찾는 부분을 '우선순위 큐'로 바꾼다면, 시간 복잡도를 O(NlogN)으로 변경할 수 있다.

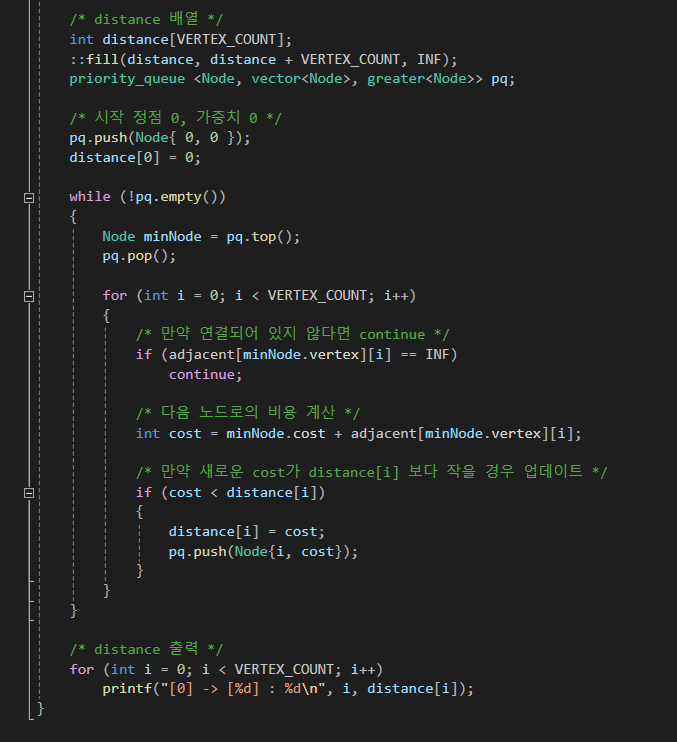
이 방법은 O(1)의 복잡도로 최소값을 얻을 수 있기에 시간 복잡도를 훨씬 줄여주고
방문 노드를 따로 기록하지 않다도 된다는 장점이 존재한다.
[5] 다익스트라 알고리즘 분석
네트워크에 n개의 정점이 있다면, O(N²)의 복잡도를 가지고,
우선순위 큐를 이용해 구현한다면 시간 복잡도는 O(ElogV) 이다.
다익스트라 알고리즘은 단점은 가중치가 음수일 때는 사용하지 못한다는 것이다.
#include <iostream>
#include <vector>
#include <algorithm>
#include <queue>
using namespace std;
const int INF = 999'999'999;
const int VERTEX_COUNT = 7;
int adjacent[VERTEX_COUNT][VERTEX_COUNT] = { 0, };
struct Node
{
bool operator>(Node other)const { return cost > other.cost; }
bool operator<(Node other) const { return cost < other.cost; }
int vertex,
cost;
};
void InsertEdge(int from, int to, int cost)
{
adjacent[from][to] = cost;
adjacent[to][from] = cost;
}
int main()
{
/* 그래프 초기화 */
for (int i = 0; i < VERTEX_COUNT; i++)
for (int j = 0; j < VERTEX_COUNT; j++)
adjacent[i][j] = INF;
/* 정점 연결 */
{
for (int i = 0; i < VERTEX_COUNT; i++)
InsertEdge(i, i, 0);
InsertEdge(0, 1, 7);
InsertEdge(0, 4, 3);
InsertEdge(0, 5, 10);
InsertEdge(1, 4, 2);
InsertEdge(1, 5, 6);
InsertEdge(1, 2, 4);
InsertEdge(1, 3, 10);
InsertEdge(2, 3, 2);
InsertEdge(3, 4, 11);
InsertEdge(3, 5, 9);
InsertEdge(3, 6, 4);
InsertEdge(4, 6, 5);
}
/* distance 배열 */
int distance[VERTEX_COUNT];
::fill(distance, distance+VERTEX_COUNT, INF);
priority_queue <Node, vector<Node>, greater<Node>> pq;
/* 시작 정점 0, 가중치 0 */
pq.push(Node{ 0, 0 });
distance[0] = 0;
while (!pq.empty())
{
Node minNode = pq.top();
pq.pop();
for (int i = 0; i < VERTEX_COUNT; i++)
{
/* 만약 연결되어 있지 않다면 continue */
if (adjacent[minNode.vertex][i] == INF)
continue;
/* 다음 노드로의 비용 계산 */
int cost = minNode.cost + adjacent[minNode.vertex][i];
/* 만약 새로운 cost가 distance[i] 보다 작을 경우 업데이트 */
if (cost < distance[i])
{
distance[i] = cost;
pq.push(Node{i, cost});
}
}
}
/* distance 출력 */
for (int i = 0; i < VERTEX_COUNT; i++)
printf("[0] -> [%d] : %d\n", i, distance[i]);
}
2) 플로이드-워셜 최단 경로 알고리즘
그래프에 존재하는 모든 정점 사이의 최단 경로를 구하려면 다익스트라의 알고리즘을 정점의 수만큼 반복 실행하면 된다.
그러나 모든 정점 사이의 최단 거리를 구하려면 더 간단하고 좋은 알고리즘이 존재한다.
바로 '플로이드-워셜 알고리즘'이다.
이는 그래프에 존재하는 모든 정점 사이의 최단 경로를 한 번에 모두 찾아주는 알고리즘이다.
Floyd의 최단 경로 알고리즘은 2차원 배열 A를 이용하여 3중 반복을 하는 루프로 구성되어 있다.
알고리즘 자체는 아주 간단하다.
먼저 인접 행렬 adjacent는 다음과 같이 만들어 진다.
i == j 이면 adjacent [i][j] = 0으로 하고 만약 두개의 정점 i, j 사이에 간선이 존재하지 않으면 adjacent [i][j] = INF라고 하자.
정점 i,j 사이에 간선이 존재하면 adjacent [i][j]가 간선 (i, j)의 가중치 행렬이 weight가 된다.
Floyd의 알고리즘은 다음과 같이 삼중 반복문으로 표현된다. 배열 A의 초기값은 가중치 행렬인 adjacent이다.

위의 알고리즘을 설명하기 위하여 A_k[i][j] 를 0부터 k까지의 정점만을 이용한 정점 i에서 j까지의 최단 경로하고 하자.
우리가 원하는 답은 A_(k-1)[i][j] 이 된다.
왜냐면 A_(k-1)[i][j] 은 0부터 k-1 까지의 모든 정점을 이용한 최단 경로이기 떄문이다.
플로이드-워셜 알고리즘의 핵심적인 아디이어는 A_(-1) -> A_(0) -> A_(1) -> ... -> A_(k-1) 순으로
최단 거리를 구하자는 것이다.
A_(-1)은 초기 adjacent 배열과 동일한 값을 가진다.
먼저 A_(k-1) 까지는 완벽한 최단 거리가 구해져 있다고 가정하자.
그리고 k 번째 정점을 더 사용할 수 있다고 가정해보자.
그러면 정점 i 에서 정점 j 로 가는 경우의 수는 2가지가 된다.

1) A_(k-1) 에서 구한 값으로 이동하기 -> A_k = A_(k-1)
2) 새로운 정점 k를 거쳐서 가기 -> A_k = adjacent[i][k] + adjacent[k][j]
따라서 최종적인 최단거리는 당연히 1)과 2) 중 더 적은 값이 될 것이다.
[2] 플로이드-워셜 알고리즘 구현

구현 자체는 매우 간단하다.
#include <iostream>
#include <vector>
#include <algorithm>
#include <queue>
using namespace std;
const int INF = 999'999'999;
const int VERTEX_COUNT = 7;
int adjacent[VERTEX_COUNT][VERTEX_COUNT] = { 0, };
struct Node
{
bool operator>(Node other)const { return cost > other.cost; }
bool operator<(Node other) const { return cost < other.cost; }
int vertex,
cost;
};
void InsertEdge(int from, int to, int cost)
{
adjacent[from][to] = cost;
adjacent[to][from] = cost;
}
int main()
{
/* 그래프 초기화 */
for (int i = 0; i < VERTEX_COUNT; i++)
for (int j = 0; j < VERTEX_COUNT; j++)
adjacent[i][j] = INF;
/* 정점 연결 */
{
for (int i = 0; i < VERTEX_COUNT; i++)
InsertEdge(i, i, 0);
InsertEdge(0, 1, 7);
InsertEdge(0, 4, 3);
InsertEdge(0, 5, 10);
InsertEdge(1, 4, 2);
InsertEdge(1, 5, 6);
InsertEdge(1, 2, 4);
InsertEdge(1, 3, 10);
InsertEdge(2, 3, 2);
InsertEdge(3, 4, 11);
InsertEdge(3, 5, 9);
InsertEdge(3, 6, 4);
InsertEdge(4, 6, 5);
}
/* 행렬 A를 가중치 행렬 adjacent 로 초기화 */
int A[VERTEX_COUNT][VERTEX_COUNT];
for (int i = 0; i < VERTEX_COUNT; i++)
for (int j = 0; j < VERTEX_COUNT; j++)
A[i][j] = adjacent[i][j];
for (int k = 0; k < VERTEX_COUNT; k++)
for (int i = 0; i < VERTEX_COUNT; i++)
for (int j = 0; j < VERTEX_COUNT; j++)
A[i][j] = min(A[i][j], A[i][k] + A[k][j]);
/* 결과 출력 */
for (int i = 0; i < VERTEX_COUNT; i++)
{
for (int j = 0; j < VERTEX_COUNT; j++)
cout << A[i][j] << " ";
cout << endl;
}
}
[3] 플로이드-워셜 최단 경로 알고리즘의 분석
두 개의 정점 사이의 최단 경로를 찾은 다익스트라의 알고리즘은 시간 복잡도가 기존 배열을 사용했을 때 (우선순위큐를 사용하지 않았을 때)
O(N²) 이 소모되고, 모든 정점 쌍을 기준으로 최단 경로를 구하려면 n번 반복해야 하므로 O(N³) 이 된다.
한 번에 모든 정점 간의 최단 경로를 구하는 플로이드-워셜 알고리즘은 3중 반복문이 실행되므로 시간 복잡도가 O(N³)으로 표현된다.
이는 다익스트라의 알고리즘과 비교해 차이는 없다고 할 수 있다. 그러나 Floyd의 알고리즘은 매우 간결한 반복 구문을 사용하므로 Dikstra의 알고리즘보다 상당히 빨리 모든 정점 간의 최단 경로를 찾을 수 있다.
4. 과제
1) 프림 알고리즘, 다익스트라 알고리즘을 인접 리스트 버전으로 구현하시오.
2) https://www.acmicpc.net/problem/1753
'스터디 자료' 카테고리의 다른 글
| [알고리즘 스터디 솔루션] 17404, 10282, 13418 (2) | 2024.05.29 |
|---|---|
| 다이나믹 프로그래밍 솔루션:: 백준 11051, 9251, 1520 (0) | 2024.05.23 |
| (공사중) 동적 계획법, 다이나믹 프로그래밍 (공사중) (0) | 2024.05.22 |
| [알고리즘 스터디] 컴퓨터 과학에서 말하는 그래프 - 上 (1) | 2024.04.27 |