참고자료: C언어로 쉽게 풀어쓴 자료구조 - 천인국 저
1. 그래프란?
그래프(graph)는 객체 사이 연결 관계를 표현할 수 있는 자료구조다.
그래프의 대표적인 예는 '지도'이다.
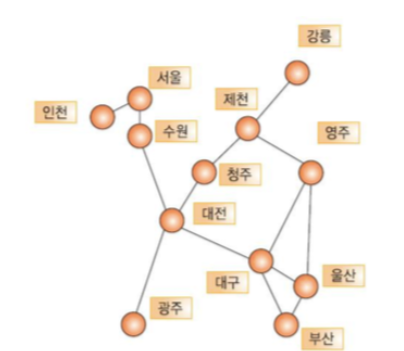
위 그림은 여러 개의 도시들이 어떻게 연결되었는지를 보여준다.
지도를 그래프로 표현하면 특정한 지역에서 다른 지역으로 가는 최단 경로를 쉽게 프로그래밍해서 찾을 수 있다.
또한 전기 소자를 그래프로 표현하게 되면 전기 회로의 소자들이 어떻게 연결되어 있는지를 표현해야 회로가 제대로 동작하는지 분석할 수 있으며, 운영 체제에서는 프로세스와 자원들이 어떻게 연관되는지를 그래프로 분석하여 시스템의 효율이나 교착상태 유무 등을 알아낼 수 있다.
그래프는 이러한 많은 문제들을 표현할 수 있는 훌륭한 논리적 도구이다.
우리가 이때까지 배워온 선형리스트나 트리의 구조로는 위와 같은 복잡한 문제를 표현할 수 없다.
그래프 구조는 '인접 행렬'이나 '인접 리스트'로 메모리에 표현되고 처리될 수 있으므로 광범위한 분야의 다양한 문제들을 그래프로 표현하여 컴퓨터 프로그래밍에 의해 해결할 수 있다.
그래프는 아주 일반적인 자료 구조로서 앞에서 배웠던 트리도 그래프의 하나의 특수한 종류로 볼 수 있다.
그래프 이론은 컴퓨터 학문 분야의 활발한 연구 주제이며 문제 해결을 위한 도구로서 많은 이론과 응용이 존재한다.
우리는 여기서 그래프의 기본적인 알고리즘에 대해서 학습한다.
2. 그래프의 역사

1736년 수학자 오일러는 "쾨니히스베르크 다리 문제"를 해결하기 위하여 그래프를 처음으로 사용하였다.
위 문제는 "임의의 지역에서 출발하여 모든 다리를 단 한번만 건너서 처음 출발했던 지역으로 돌아올 수 있는가?"이다.
많은 사람들이 이 문제의 답을 찾기 위해 노력했지만, 방법은 없다는 것이 정답이다.
오일러는 어떤 한 지역에서 시작하여 모든 다리를 한 번 씩만 지나서 처음 출발점으로 되돌아오려면 각 지역에 연결된 다리의 개수가 모두 짝수이어야 함을 증명하였다.
오일러는 위의 문제를 다음과 같이 간단하게 변경하였다.
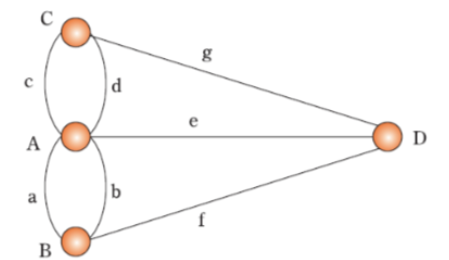
오일러는 이 문제에서 핵심적으로 중요한 것은 'A, B, C, D의 위치가 어떠한 관계로 연결되었는가?'라고 생각하고,
특정 지역은 정점(node)로, 다리는 간선(edge)으로 표현하여 위 그림과 같은 그래프 문제로 변환하였따.
오일러는 이러한 그래프에 존재하는 모든 간선을 한번만 통과하면서 처음 정점으로 되돌아오는 경로를 오일러 경로라 정의하고, 그래프의 모든 정점에 연결된 간선의 개수가 짝수일 때만 오일러 경로가 존재한다는 오일러의 정리를 증명하였다.
3. 그래프의 정의
그래프는 정점과 간선의 유한 집합으로 정의한다.
정점(Vertex, Node)는 여러 가지 특성을 가질 수 있는 객체를 의미하고
간선(Edge, Adjacent, Link)는 이러한 정점들 간의 관계를 의미한다.
많은 자료에서 다양한 단어가 혼용되니 이에 주의하도록 한다.
수학적으로 그래프 G는
G = (V, E) 로 정의할 수 있다.
V(G)는 그래프 G의 정점들의 집합을
E(G)는 그래프 G의 간선들의 집합을 의미한다.
[1] 무방향 그래프와 방향 그래프

간선의 종류에 따라 그래프는 '무방향 그래프'와 '방향 그래프'로 구분된다.
무방향 그래프의 간선은 간선을 통해서 양방향으로 갈 수 있음을 나타내며
정점 1과 2를 연결하는 간선은 (1, 2)와 같이 정점의 쌍으로 표현한다.
무방향 그래프에서는 (1, 2)와 (2, 1)가 동일한 간선을 의미한다.
방향 그래프는 간선에 방향성이 존재하는, 마치 일방통행길과 같은 의미를 띈다.
방향 그래프에서는 간선을 통하여 한쪽 방향으로만 갈 수 있다.
정점 1과 정점 2로만 갈 수 있는 간선은 <1,2>로 표시한다.
방향 그래프에선 <1,2>와 <2,1>이 서로 다른 간선이다.
[2] 가중치 그래프 (Weighted Graph, Network)
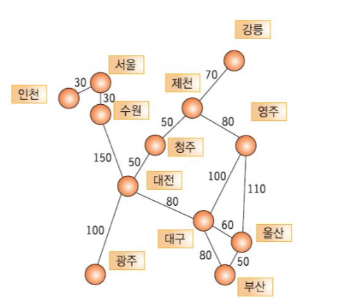
간선에 가중치를 할당하게 되면, 간선의 역할이 두 정점간의 연결 유무뿐만 아니라 연결 강도까지 나타낼 수 있으므로 보다 복잡한 관계를 표현할 수 있게 된다.
이렇게 간선에 비용이나 가중치가 할당된 그래프를 가중치 그래프 혹은 네트워크라고 부른다.
가중치 그래프는 도시와 도시를 연결하는 도로의 길이, 회로 소자의 용량, 통신망의 사용료 등을 추가로 표현할 수 있으므로 그 응용 분야가 보다 광범위하다.
[3] 부분 그래프 (Subgraph)

어떤 그래프의 정점의 일부와 간선의 일부로 이루어진 그래프를 부분 그래프라 한다.
[4] 정점의 차수 (Adjacent Vertex)
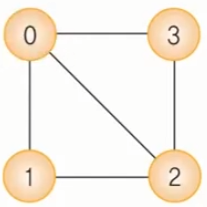
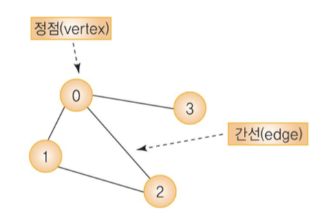
그래프에서 간선에 의해 연결된 정점은 서로 인접하다 라고 말할 수 있다.
위 그림에서 정점 0의 인접 정점은 정점 1, 2, 3 이다.
무방향 그래프에서 정점의 차수는 그 정점에 인접한 정점의 수를 말한다.
무방향 그래프에서는 모든 정점의 차수를 합하면 간선 수의 2배가 된다.
방향 그래프에서는 외부에서 오는 간선의 개수를 진입 차수(in-degree)
외부로 향하는 간선의 개수를 진출 차수(out-degree)라 한다.
[5] 경로

무방향 그래프에서 정점 s로 부터 정점 e까지의 경로는 정점의 나열 s, v1, v2, v3 ... vk, e 로서
나열된 정점들 간에는 반드시 간선 (s, v1), (v1, v2), (v2, v3) ... (vk, e) 가 존재해야 한다.
즉, 위 그림에서
0,1,2,3 은 경로이지만
0,1,3,2 는 경로가 아니다. (간선 (1,3) 이 존재하지 않기 때문이다.)
경로 중에서 반복되는 간선이 없을 경우에 이러한 경로를 단순 경로
만약 단순 경로의 시작 정점과 종료 정점이 동일하다면 이러한 경로를 사이클이라 한다.
[6] 연결 그래프
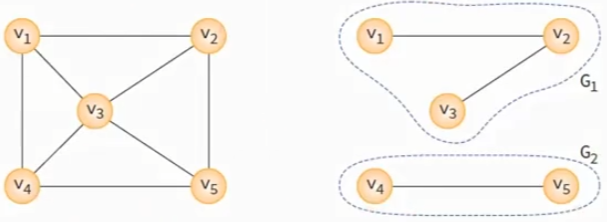
무방향 그래프 G에 있는 모든 정점쌍에 대하여 항상 경로가 존재한다면 G는 연결되었다고 말하며
이러한 무방향 그래프를 연결 그래프라 부른다.
그렇지 않은 그래프는 비연결 그래프라고 한다.
트리는 그래프의 특수한 형태로서 사이클을 가지지 않는 연결 그래프다.
만약, 그래프에 속해있는 모든 정점이 서로 연결되어 있다면
그런 그래프를 완전 그래프라 한다.
무방향 완전 그래프의 정점 수를 n이라고 하면, 하나의 정점은 n-1개의 다른 정점으로 연결되므로
간선의 수는 n x (n-1) / 2 가 된다.
4. 그래프의 표현 방법
그래프를 표현하는 방법에는 다음과 같이 2가지 방법이 있다.
그래프 문제의 특성에 따라 2가지 표현 방법은 메모리 사용량과 처리 시간 등에서 장단점을 가지므로,
문제에 적합한 표현 방법을 선택해야 한다.
- 인접 행렬(adjacency matrix): 2차원 배열을 사용하여 그래프를 표현한다.
- 인접 리스트(adjacency list): 연결 리스트를 사용하는 그래프를 표현한다.
[1] 인접행렬
그래프의 정점 수가 n이라면 n x n 의 2차원 배열인 인접 행렬 M의 각 원소를 다음의 규칙에 의해 할당함으로서 그래프를 메모리에 표현할 수 있다.

우리가 다루고 있는 그래프에서는 자체 간선을 허용하지 않으므로 인접 행렬의 대각선 성분은 모두 0으로 표신된다.

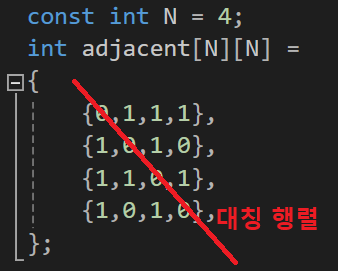
무방향 그래프의 인접 행렬은 대칭 행렬이 된다.이는 무방향 그래프의 간선 (i, j)는 정점 i에서 정점 j로의 연결뿐만 아니라 정점 j에서 정점 i로의 연결을 동시에 의미하기 때문이다.
따라서, 무방향 그래프의 경우, 배열의 상위 삼각이나 하위 삼각만 저장하면 메모리를 절약할 수 있다.

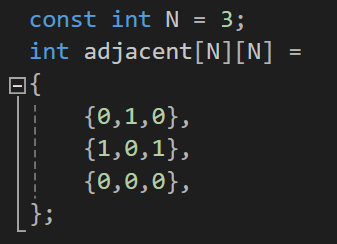
위와같은 방향 그래프의 경우 인접 행렬은 일반적으로 대칭이 아니다.
n개의 정점을 가지는 그래프를 인접 행렬로 표현하기 위해서는 간선의 수에 무관하게 항상 n² 의 메모리 공간이 필요하다.
그러므로 그래프 내에 간선이 많이 존재하는 밀집 그래프(dense graph)를 표현하는데는 인접 행렬이 적절하나
간선이 적은 희소 그래프(sparse graph)의 경우에는 메모리 낭비가 크므로 적합하지 않다.
인접 행렬의 장점은 두 정점을 연결하는 간선의 존재 여부를 O(1) 시간 안에 즉시 알 수 있다는 점이다.
또한 정점의 차수는 인접 행렬의 행이나 열을 조사하면 알 수 있으므로 O(n) 의 연산이 소모된다.
반면에 그래프에 존재하는 모든 간선의 수를 알아내려면 인접 행렬 전체를 조사해야 하므로 n²의 시간이 요구된다.
[2] 인접 행렬의 ADT

#include <iostream>
#include <cassert>
using namespace std;
#define MAX_VERTICES 50
class MyGraph
{
public:
MyGraph(int vertexCnt) : vertices(vertexCnt)
{
for (int i = 0; i < vertices; i++)
for (int j = 0; j < vertices; j++)
adjacent[i][j] = 0;
};
/* 간선 삽입 */
void InsertEdge(int from, int to)
{
/* 예외처리 */
assert(from < vertices && to < vertices);
adjacent[from][to] = 1;
adjacent[to][from] = 1;
}
/* 간선 삭제 */
void RemoveEdge(int from, int to)
{
/* 예외처리 */
assert(from < vertices && to < vertices);
adjacent[from][to] = 0;
adjacent[to][from] = 0;
}
/* 정점 삽입 */
void AddVertex()
{
assert(vertices < MAX_VERTICES);
++vertices;
for (int i = 0; i < vertices; i++)
{
adjacent[vertices - 1][i] = 0;
adjacent[i][vertices - 1] = 0;
}
}
/* 인접행렬 출력 */
void PrintGraph()
{
for (int i = 0; i < vertices; i++)
{
for (int j = 0; j < vertices; j++)
cout << adjacent[i][j] << " ";
cout << endl;
}
}
private:
int vertices;
int adjacent[MAX_VERTICES][MAX_VERTICES];
};
int main()
{
MyGraph g(3);
g.AddVertex();
g.InsertEdge(0, 1);
g.InsertEdge(0, 2);
g.InsertEdge(0, 1);
g.InsertEdge(1, 2);
g.InsertEdge(2, 3);
g.PrintGraph();
}
[3] 인접 리스트
인접 리스트는 그래프를 표현함에 있어 각각의 정점에 인접한 정점들을 연결 리스트로 표시한 것이다.
각 연결 리스트의 노드들은 인접 정점을 저장하게 된다.
각 연결 리스트들은 헤더 노드를 가지고 있고 이 헤더 노드들은 하나의 배열로 구성되어 있다.
따라서 정점의 번호만 알면 이 번호를 배열의 인덱스로 하여 각 정점의 연결 리스트에 쉽게 접근할 수 있다.
무방향 그래프의 경우 정점 i와 정점 j를 연결하는 간선 (i, j)는 정점 i의 연결 리스트에 인접 정점 j로서 한번 표현되고,
정점 j의 연결 리스트에 인접 정점 i로 다시 한번 표현된다.
연결 리스트의 각각의 연결 리스트에 정점들이 입력되는 순서에 따라 연결 리스트 내에서 정점들의 순서가 달라질 수 있다.

따라서 정점의 수가 n 개이고 간선의 수가 e개인 무방향 그래프를 표시하기 위해서는 n개의 연결 리스트가 필요하고, n개의 헤더 노드와 2e개의 노드가 필요하다.
따라서 인접 행렬 표현은 간선의 개수가 적인 희소 그래프의 표현에 적합하다.
그래프에 간선 (i,j)의 존재 여부나 정점 i의 차수를 알기 위해서는 인접 리스트에서의 정점 i의 연결 리스트를 탐색해야 하므로 연결 리스트에 있는 노드의 수만큼이 필요하다.
즉 n개 정점과 e개의 간선을 가진 그래프에서 전체 간선의 수를 알아내려면 헤더 노드를 포함하여 모든 인접 리스트를 조사해야 하므로 O(n+e) 의 연산이 요구된다.
[4] 인접 리스트의 ADT
참고: 연결리스트는 따로 구현하지 않고, list 라는 STL을 사용하였음. vector을 사용해도 무관
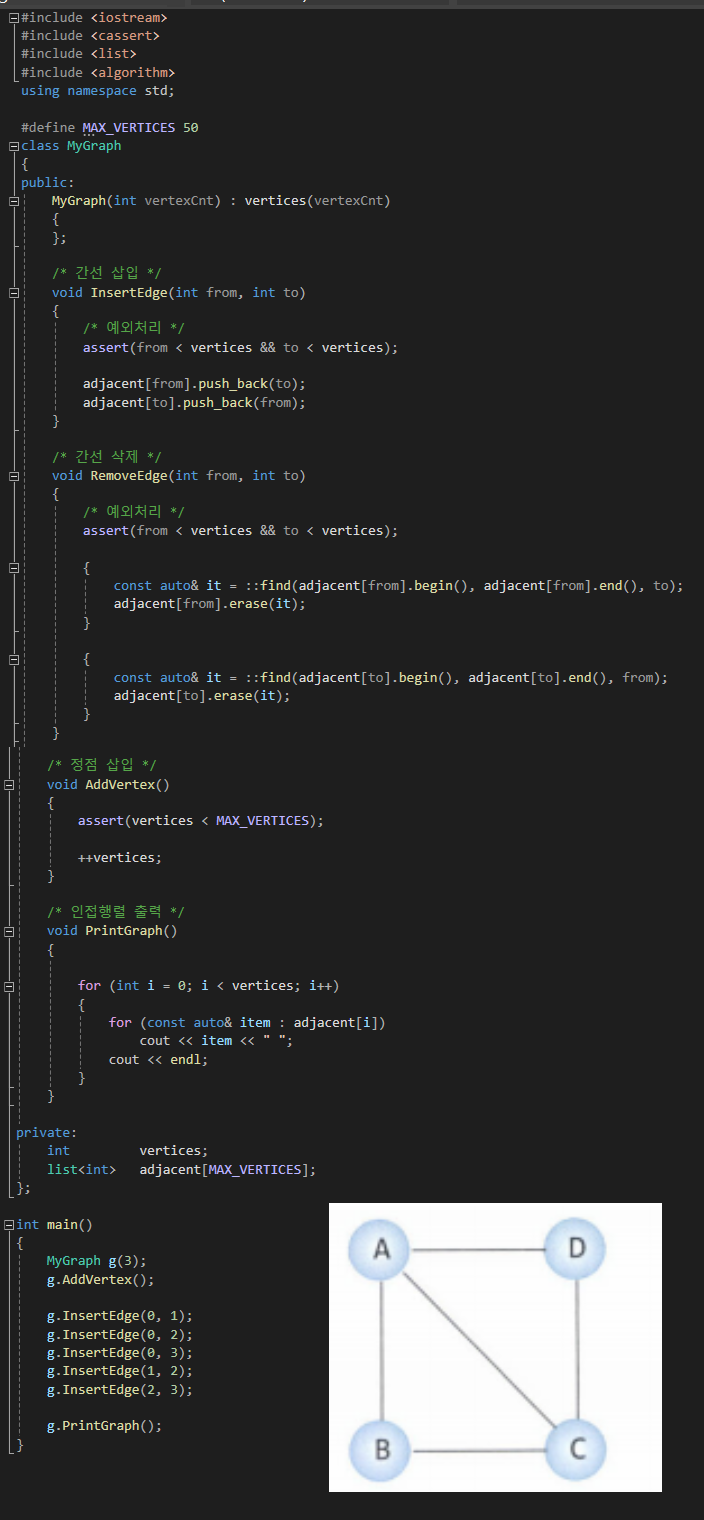
#include <iostream>
#include <cassert>
#include <list>
#include <algorithm>
using namespace std;
#define MAX_VERTICES 50
class MyGraph
{
public:
MyGraph(int vertexCnt) : vertices(vertexCnt)
{
};
/* 간선 삽입 */
void InsertEdge(int from, int to)
{
/* 예외처리 */
assert(from < vertices && to < vertices);
adjacent[from].push_back(to);
adjacent[to].push_back(from);
}
/* 간선 삭제 */
void RemoveEdge(int from, int to)
{
/* 예외처리 */
assert(from < vertices && to < vertices);
{
const auto& it = ::find(adjacent[from].begin(), adjacent[from].end(), to);
adjacent[from].erase(it);
}
{
const auto& it = ::find(adjacent[to].begin(), adjacent[to].end(), from);
adjacent[to].erase(it);
}
}
/* 정점 삽입 */
void AddVertex()
{
assert(vertices < MAX_VERTICES);
++vertices;
}
/* 인접행렬 출력 */
void PrintGraph()
{
for (int i = 0; i < vertices; i++)
{
for (const auto& item : adjacent[i])
cout << item << " ";
cout << endl;
}
}
private:
int vertices;
list<int> adjacent[MAX_VERTICES];
};
int main()
{
MyGraph g(3);
g.AddVertex();
g.InsertEdge(0, 1);
g.InsertEdge(0, 2);
g.InsertEdge(0, 3);
g.InsertEdge(1, 2);
g.InsertEdge(2, 3);
g.PrintGraph();
}
5. 그래프의 탐색
그래프 탐색은 가장 기본적인 연산으로서 하나의 정점으로부터 시작하여 차례대로 모든 정점들을 한 번씩 방문하는 것이다. 그래프 탐색은 아주 중요하다. 많은 문제들이 단순히 그래프의 노드를 탐색하는 것으로 해결된다.
대표적으로 특정한 정점에서 다른 정점으로 갈 수 있는지 없는지, 전자 회로에서 특정 단자와 단자가 서로 연결되어 있는지를 탐색을 통하여 알 수 있다.
그래프의 탐색 방법은 깊이 우선 탐색 DFS과 너비 우선 탐색 BFS의 두 가지가 있다.
(1) 깊이 우선 탐색
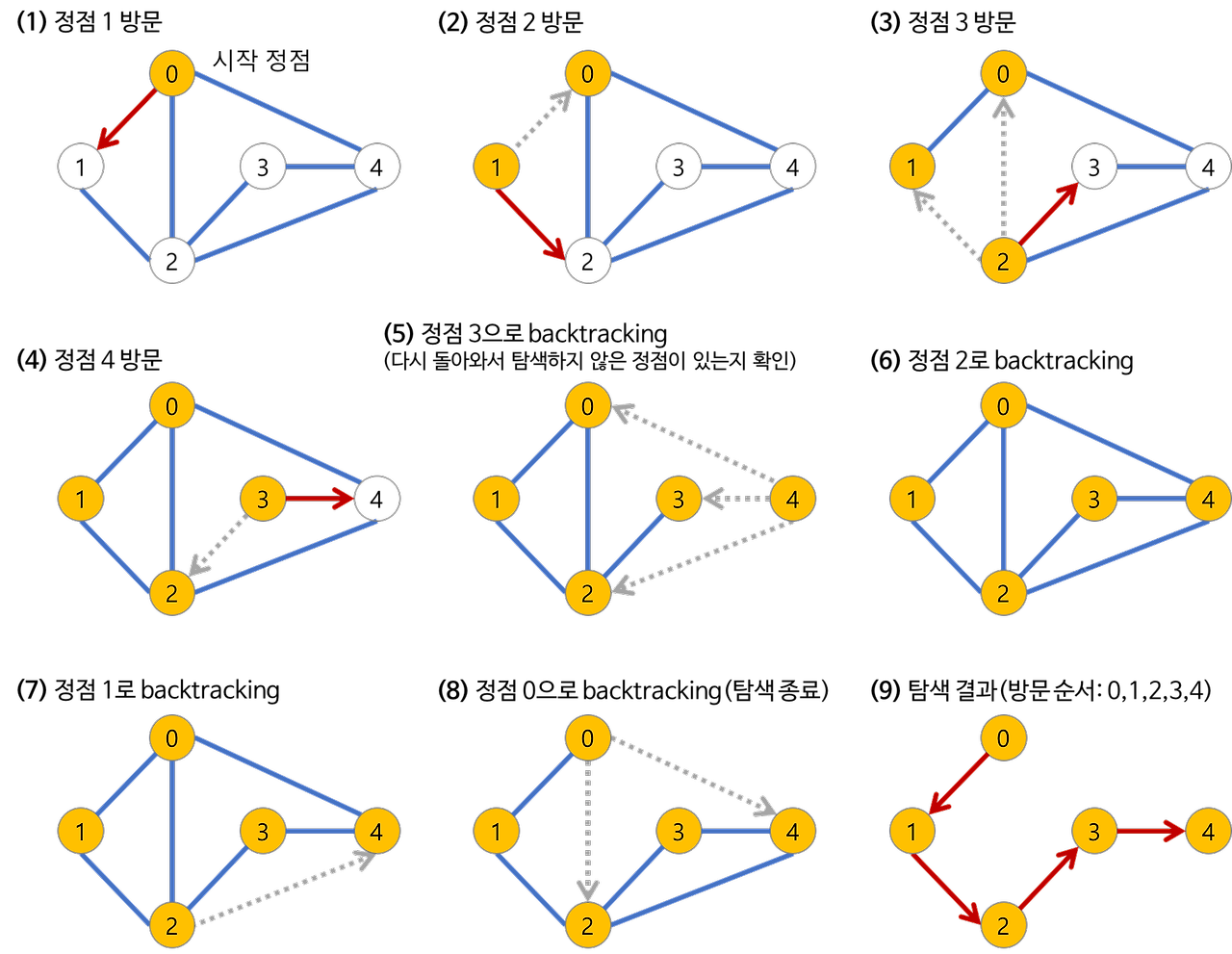
그래프에서 깊이 우선 탐색은 어떻게 진행될까?
깊이 우선 탐색은 그래프의 시작 정점에서 출발하여 시작 점점 v를 방문하였다고 표시한다.
이어서 v에 인접한 정점들 중에서 아직 방문하지 않은 정점 u를 선택한다.
만약 그러한 정점이 없다면 탐색은 종료한다.
만약 아직 방문하지 않은 정점 u가 있다면 u를 기준으로 깊이 우선 탐색을 다시 시작한다.
이 탐색이 끝나게 되면 다시 v에 인접한 정점들 중에서 아직 방문이 안 된 정점을 찾는다.
만약 없으면 종료하고 있다면 다시 그 정점을 시작 정점으로 하여 깊이 우선 탐색을 다시 시작한다.
깊이 우선 탐색도 자기 자신을 다시 호출하는 순환 알고리즘 형태를 가지고 있다.
[1] 인접 행렬 버전의 깊이 우선 탐색

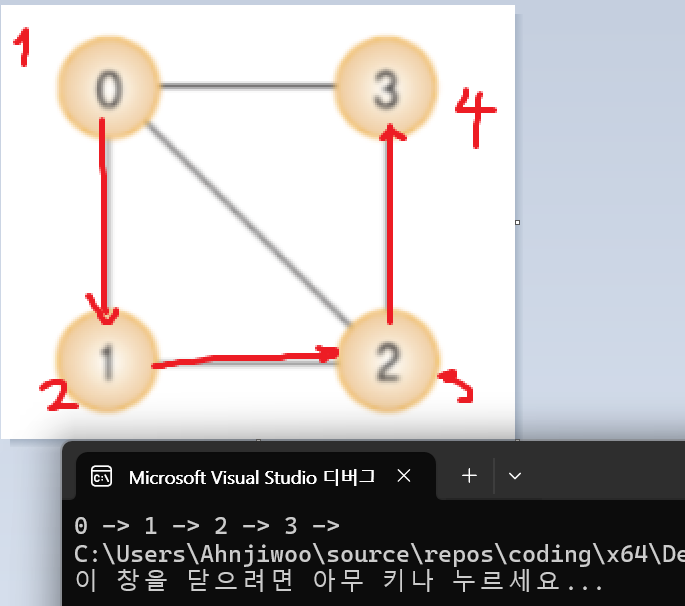
#include <iostream>
#include <cassert>
using namespace std;
#define MAX_VERTICES 50
class MyGraph
{
public:
MyGraph(int vertexCnt) : vertices(vertexCnt)
{
for (int i = 0; i < vertices; i++)
for (int j = 0; j < vertices; j++)
adjacent[i][j] = 0;
};
/* 간선 삽입 */
void InsertEdge(int from, int to)
{
/* 예외처리 */
assert(from < vertices && to < vertices);
adjacent[from][to] = 1;
adjacent[to][from] = 1;
}
/* 간선 삭제 */
void RemoveEdge(int from, int to)
{
/* 예외처리 */
assert(from < vertices && to < vertices);
adjacent[from][to] = 0;
adjacent[to][from] = 0;
}
/* 정점 삽입 */
void AddVertex()
{
assert(vertices < MAX_VERTICES);
++vertices;
for (int i = 0; i < vertices; i++)
{
adjacent[vertices - 1][i] = 0;
adjacent[i][vertices - 1] = 0;
}
}
/* 인접행렬 출력 */
void PrintGraph()
{
for (int i = 0; i < vertices; i++)
{
for (int j = 0; j < vertices; j++)
cout << adjacent[i][j] << " ";
cout << endl;
}
}
void DFS(int vertex, int* visited)
{
cout << vertex << " -> ";
visited[vertex] = 1;
for(int i=0;i<vertices;i++)
if (adjacent[vertex][i] == 1 && visited[i] == 0)
DFS(i, visited);
}
private:
int vertices;
int adjacent[MAX_VERTICES][MAX_VERTICES];
};
int main()
{
MyGraph g(4);
g.InsertEdge(0, 1);
g.InsertEdge(0, 2);
g.InsertEdge(0, 1);
g.InsertEdge(1, 2);
g.InsertEdge(2, 3);
int visited[MAX_VERTICES];
::fill(visited, visited + MAX_VERTICES, 0);
g.DFS(0, visited);
}
방문 여부를 기록하기 위해 배열 visited를 사용하며, 모든 정점의 visited 배열값은 false 로 초기화되고
정점이 방문될 떄마다 해당 정점의 visitied 배열값은 TRUE로 변경된다.
또한 그래프가 인접 행렬 또는 인접 리스트로 표현되었는가에 따라 깊이 우선 탐색 프로그램이 약간 달라지는데,
여기서는 먼저 인접 행렬을 이용하여 그래프가 표현되었다고 가정하고 깊이 우선 탐색 프로그램을 구현하였다.
[2] 분석
깊이 우선 탐색은 그래프의 모든 간선을 조사하므로 정점의 수가 n이고 간선의 수가 e인 그래프인 경우,
그래프가 인접 리스트로 표현되어 있다면 시간 복잡도가 O(n+e) 이고,
인접 행렬로 표시되어 있다면 O(n²) 이다.
이는 희소 그래프인 경우 깊이 우선 탐색은 인접 리스트의 사용이 인접 행렬보다 시간적으로 유리함을 뜻한다.
[3] 과제
1) 인접 리스트와 재귀를 활용하여 DFS를 구현해보자
2) 인접 행렬과 스택을 활용하여 DFS를 구현해보자
(2) 너비 우선 탐색
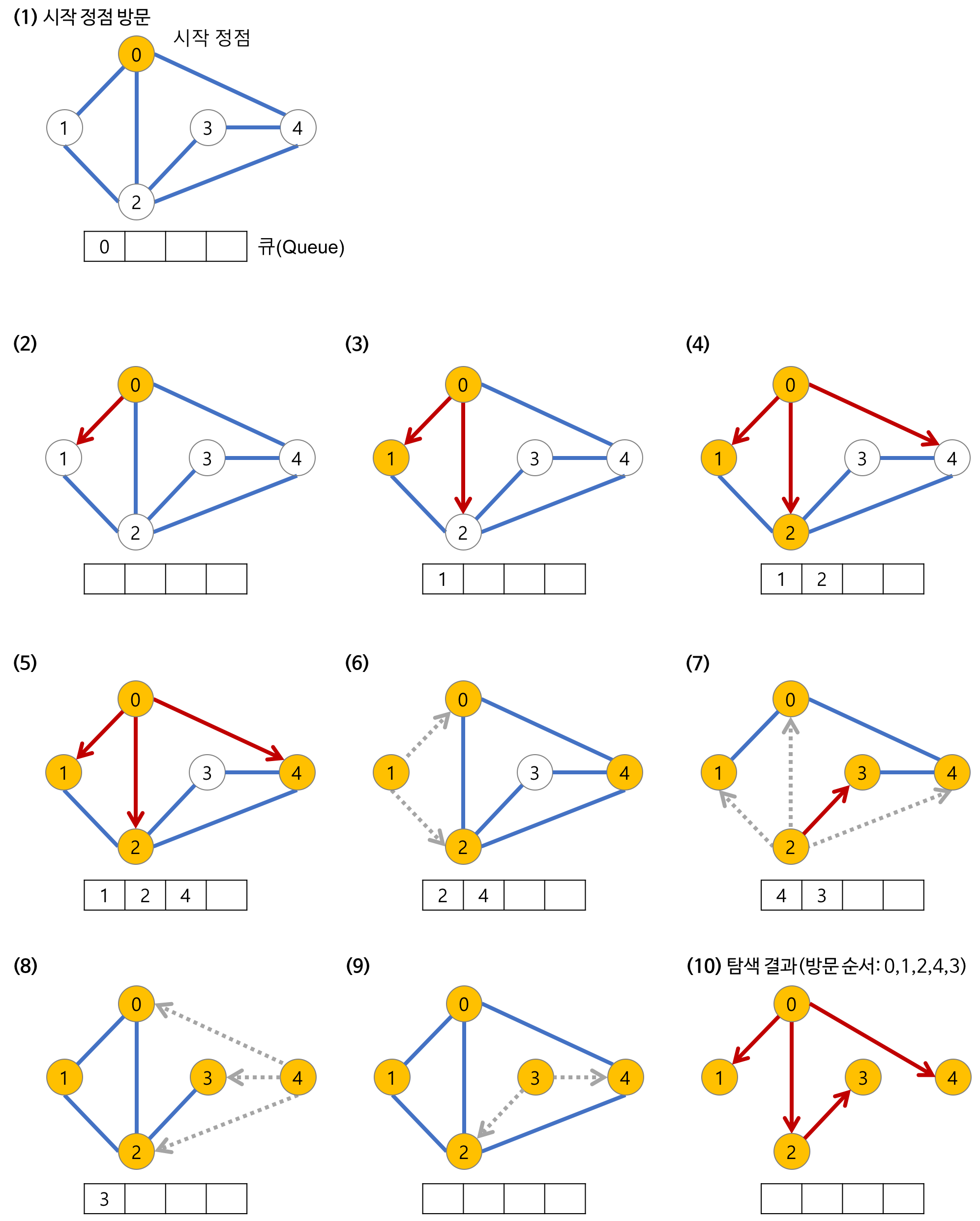
너비 우선 탐색은 시작 정점으로부터 가까운 정점을 먼저 방문하고
멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법이다.
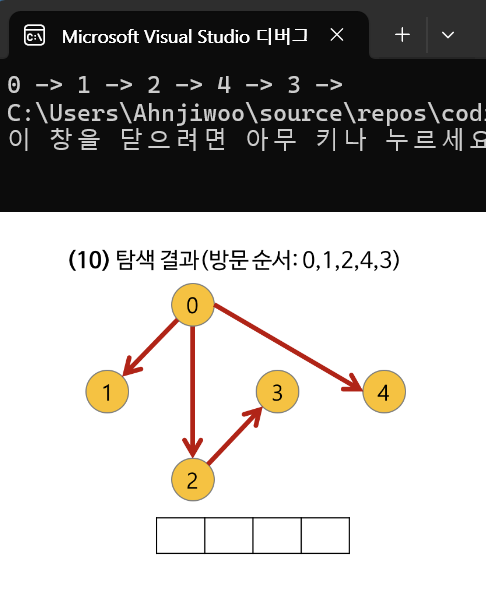
위 그래프를 BFS로 방문한다고 가정하자,
그러면 시작 정점인 0을 방문한다.
그 다음 0과 인접한 정점인 1, 4를 차례로 방문한다.
그 다음으로 1, 4와 인접한 정점인 2, 3을 방문한다.
너비 우선 탐색을 위해서는 가까운 거리에 있는 정점들을 차례로 저장한 후 꺼낼 수 있는 자료구조인 큐가 필요하다.
알고리즘은 무조건 큐에서 정점을 꺼내서 정점을 방문하고 인접 정점들을 큐에 추가한다.
큐가 소진될 때까지 동일한 코드를 반복한다.
[1] 인접 행렬 버전 너비 우선 탐색 구현

#include <iostream>
#include <cassert>
#include <queue>
using namespace std;
#define MAX_VERTICES 50
class MyGraph
{
public:
MyGraph(int vertexCnt) : vertices(vertexCnt)
{
for (int i = 0; i < vertices; i++)
for (int j = 0; j < vertices; j++)
adjacent[i][j] = 0;
};
/* 간선 삽입 */
void InsertEdge(int from, int to)
{
/* 예외처리 */
assert(from < vertices && to < vertices);
adjacent[from][to] = 1;
adjacent[to][from] = 1;
}
/* 간선 삭제 */
void RemoveEdge(int from, int to)
{
/* 예외처리 */
assert(from < vertices && to < vertices);
adjacent[from][to] = 0;
adjacent[to][from] = 0;
}
/* 정점 삽입 */
void AddVertex()
{
assert(vertices < MAX_VERTICES);
++vertices;
for (int i = 0; i < vertices; i++)
{
adjacent[vertices - 1][i] = 0;
adjacent[i][vertices - 1] = 0;
}
}
/* 인접행렬 출력 */
void PrintGraph()
{
for (int i = 0; i < vertices; i++)
{
for (int j = 0; j < vertices; j++)
cout << adjacent[i][j] << " ";
cout << endl;
}
}
void BFS(int start)
{
queue<int> q;
bool discovered[MAX_VERTICES];
::fill(discovered, discovered + MAX_VERTICES, false);
q.push(start);
discovered[start] = true;
while (!q.empty())
{
int here = q.front();
q.pop();
cout << here << " -> ";
for (int there = 0; there < vertices; there++)
{
if (discovered[there] == true || adjacent[here][there] == 0) continue;
q.push(there);
discovered[there] = true;
}
}
}
private:
int vertices;
int adjacent[MAX_VERTICES][MAX_VERTICES];
};
int main()
{
MyGraph g(5);
g.InsertEdge(0, 1);
g.InsertEdge(0, 2);
g.InsertEdge(0, 4);
g.InsertEdge(1, 2);
g.InsertEdge(2, 3);
g.InsertEdge(3, 4);
g.BFS(0);
}
[2] 분석
너비 우선 탐색은 그래프가 인접 리스트로 표현되어 있으면 전체 수행시간이 O(n+e)이며, 인접 행렬로 표현되어 있는 경우는 O(n²) 시간이 걸린다. 너비우선 탐색도 깊이우선 탐색과 같이 희소 그래프를 사용할 경우 인접리스트를 사용하는 것이 효율적이다.
[3] 과제
https://www.acmicpc.net/problem/1260
https://www.acmicpc.net/problem/2606
'스터디 자료' 카테고리의 다른 글
| [알고리즘 스터디 솔루션] 17404, 10282, 13418 (2) | 2024.05.29 |
|---|---|
| 다이나믹 프로그래밍 솔루션:: 백준 11051, 9251, 1520 (0) | 2024.05.23 |
| (공사중) 동적 계획법, 다이나믹 프로그래밍 (공사중) (0) | 2024.05.22 |
| [알고리즘 스터디] 컴퓨터 과학에서 말하는 그래프 - 下 (1) | 2024.04.28 |