이 장에서는 실시간 그래픽의 핵심 구성 요소인 그래픽 렌더링 파이프라인 (간단히 파이프라인)에 대해서 소개한다.
렌더링 파이프라인의 주요 기능은 '가상 카메라', '3차원 객체', '광원' 등을 제공받아 2차원 이미지를 생성하고 렌더링하는 것이다. 따라서 '렌더링 파이프라인'이란 실시간 렌더링의 기본적인 도구이다. (핵심 기술이라고 설명할 수 있다.)
렌더링된 이미지에서 객체의 위치와 형태는 오브젝트의 기하학적 모양(Geometry), 환경의 특성, 카메라의 배치등에 따라 결정되고, 오브젝트의 외관은 재질 속성(Material), 광원, 텍스처 및 음영 방정식에 의해 결정된다.
(음영 방정식 Shading equation 은 광원, 물체 표면, 관찰자 간의 상호작용을 기반으로 최종 색상을 계산하는 방정식을 뜻하며 기본적으로 픽셀 쉐이더에 적용되는 수학적 코드의 흐름 정도로 해석할 수 있다.)
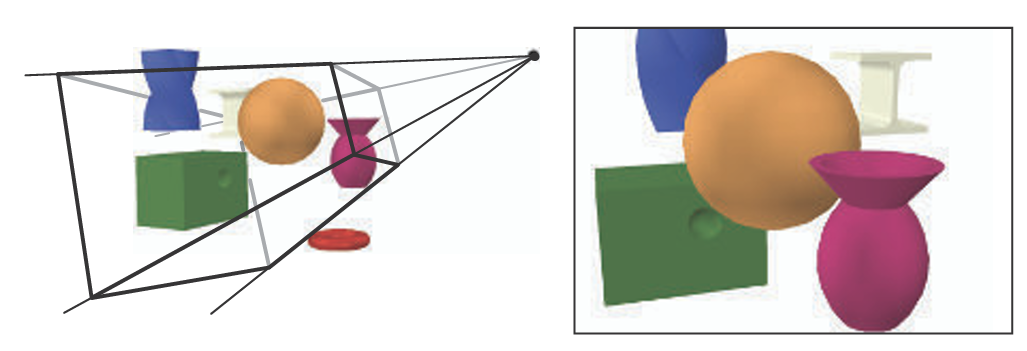
왼쪽 이미지에서 가상 카메라는 피라미드의 꼭대기에 위치해 있다. View Volume 내부에 있는 프리미티브만 렌더링된다.
오른쪽 이미지는 카메라가 보는 모습을 보여준다. 왼쪽 이미지의 빨간 도넛 모양은 시야 프러스텀 외부에 위치해 있기에 오른쪽 렌더링에 포함되지 않는다. 또한, 왼쪽 이미지의 비틀린 파란 프리즘은 프러스텀 상단 평면에 잘려 나갔다.
우리는 구현보다는 기능에 중점을 두고 렌더링 파이프라인의 다양한 단계를 설명할 것이다.
세부사항은 이후에 다룬다.
아키텍처

실세계에서 파이프라인 개념은 공장 조립 라인, 패스트푸드 주방 등 다양한 형태로 나타난다.
그래픽 렌더링에서도 마찬가지다. 파이프라인은 여러 단계로 구성되며 각 단계는 전체 작업을 일부를 수행한다.
파이프라인의 각 단계는 병렬로 실행되며, 각 단계는 이전 단계의 결과를 사용한다. 이상적으로, 파이프라인 되지 않는 과정을 n개의 파이프라인 단계로 나누면 성능이 n배 빨라질 수 있다. 그래서 여러 컴퓨터 아키텍처에서 파이프라인 형태를 사용하는 것이다. 파이프라인 단계는 병렬로 실행되지만, 가장 느린 단계가 작업을 완료할 때까지 멈추게 된다. 이런 stall을 bottleneck이라고 한다. (stall 말고 starving 이라는 표현을 쓰기도 한다.)
이러한 파이프라인 구조가 실시간 컴퓨터 그래픽스에서 어떻게 적용되는가? 실시간 렌더링 파이프라인은 크게 4개의 주요 단계로 나누어 진다.
Application - Geometry Processing - Raterization - Pixel Processing
(애플리케이션, 지오메트리 프로세싱, 래스터화, 픽셀 프로세싱)
이러한 각 단계는 지오메트리 처리 단계의 아래 그림과 같이 그 단계 자체로 하나의 파이프라인일 수도 있고, 픽셀 처리와 같이 단계가 부분적으로 병렬화될 수도 있다. 위 그림에서 애플리케이션 단계는 단일 프로세스이지만 이 단계 또한 파이프라인화 또는 병렬화될 수 있다.
렌더링 속도는 초당 프레임 수 (FPS)로 표현될 수 있다. 또한, Hz를 사용하여 표현할 수도 있는데, 이는 단순히 업데이트 빈도를 나타내는 표기법이다. 혹은 이미지를 렌더링하는 데 걸리는 시간을 ms 로 나타내는 것도 일반적이다. (delta time) 이미지를 생성하는 데 걸리는 시간은 보통 각 프레임 동안 수행되는 계산의 복잡성에 따라 달라진다. 초당 프레임 수는 특정 프레임의 속도를 나타내거나 일정 기간 동안의 평균 성능을 표현하는 데 사용된다. 헤르츠는 고정 속도로 설정된 디스플레이와 같은 하드웨어에 사용된다.
이름에서 알 수 있듯, Application 단계는 일반적으로 CPU에서 실행되는 소프트웨어로 구현된다. 이러한 CPU는 일반적으로 여러 코어를 포함하고 있어 병렬로 여러 실행 스레드를 처리할 수 있다. 전통적으로 CPU에서 수행되는 작업에는 충돌 감지, 전역 가속 알고리즘, 애니메이션, 물리 시뮬레이션 등 애플리케이션의 유형에 따라 다양한 작업이 포함된다.
(일반적으로 프로그래머가 코딩하는 부분이다.)
다음 주요 단계는 Geometry Processing 단계로 변환(transform) ,투영(perspective) 및 기타 유형의 기하학적 처리를 다룬다. 이 단계는 무엇을 어떻게 어디에 그릴지를 계산한다. 기하학 단계는 일반적으로 많은 programmable core (Vertex Shader)와 고정 작업 하드웨어를 포함한 GPU에서 수행된다.
Rasterization 단계는 일반적으로 세 개의 정점을 입력으로 받아 삼각형을 형성하고, 해당 삼각형 내부에 있는 것으로 간주되는 모든 픽셀을 찾아 다음 단계로 전달한다.
Pixel Processing 단계는 픽셀별로 프로그램을 실행하여 색상을 결정하며, 픽셀이 보이는지 여부를 확인하기 위해 깊이 테스트를 수행할 수도 있고, 새로 계산된 색상을 이전 색상과 블랜딩 하는 등 픽셀별 작업을 수행할 수 있다.
레스터화, 픽셀 처리 모두 GPU에서 처리된다.
애플리케이션 단계 (Application Stage)
애플리케이션 단계는 일반적으로 CPU에서 실행되기 때문에, 개발자가 이 단계에서 발생하는 모든 것을 완전히 제어할 수 있다. 따라서 개발자는 구현을 완전히 결정할 수 있으며, 나중에 성능을 개선하기 위해 수정할 수 도 있다. 이 단계의 변경 사항은 이후 단계의 성능에도 영향을 줄 수 있다. 예를 들어, 어플리케이션 단계의 알고리즘이나 설정을 통해 렌더링할 삼각형의 개수를 줄일 수 있다.
이와는 별도로, 일부 애플리케이션 작업은 컴퓨트 쉐이더라는 별도의 모드를 사용하여 GPU에서 수행할 수도 있다. 이 모드는 GPU를 그래픽 렌더링을 위한 특수한 장치가 아닌 고도로 병렬화된 범용 프로세서로 취급할 수 있게 한다.
애플리케이션 단계가 끝나면 렌더링할 Geometry 데이터가 Geometry processing 단계로 전달된다. 전달된 데이터는 출력 장에 표시될 가능성이 있기 때문에, 기하 데이터를 전달하는 것은 애플리케이션 단계에서 가장 중요한 작업으로 간주된다.
소프트웨어 기반으로 구현되는 이 단계의 결과는 지오메트리 프로세싱, 래스터화, 픽셀 처리 단계와 달리 하위 단계로 나뉘지 않는다. 하지만 성능을 높이기 위해 이 단계는 종종 병렬로 실행되며, CPU 설계에서 이를 슈퍼스칼라 구조라고 하며, 동일한 단계에서 여러 프로세스를 동시에 실행할 수 있다. (앞서 애플리케이션 단계를 별도의 파이프라인으로 만들 수 있다고 언급했으나 이는 100% 전적으로 프로그래머의 역량에 달려있다.)
이 단계에서 일반적으로 구현되는 한 가지 프로세스는 충돌 감지이다. 두 객체 간 충돌이 감지되면, 반응이 생성되어 충돌한 객체뿐만 아니라 힘 피드백 장치에도 전달될 수 있다. 또한, 이 단계는 키보드, 마우스, 헤드 마운트 디스플레이와 같은 다른 입력 장치의 입력을 처리하는 역할도 담당한다. 이 입력에 따라 다양한 작업이 수행될 수 있다.
특정 컬링 알고리즘과 같은 가속 알고리즘도 이 단계에서 구현되며, 파이프라인의 다른 부분에서 처리할 수 없는 작업도 이곳에서 수행된다.
기하학 처리 단계 (Geometry Processing)

GPU에서 기하학 처리 단계는 대부분 삼각형 단위, 정점 단위 작업을 담당한다. 이 단계는 추가적으로 다음과 같은 기능적 단계로 나뉜다.
버텍스 쉐이딩 - 투영 - 클리핑 - 스크린 매핑
버텍스 쉐이딩의 주요 작업은 크게 두 가지이다.
1) 버텍스의 위치를 계산하는 것
2) 버텍스의 출력 데이터를 계산하는 것 (대상은 Normal, UV 좌표 등.. 버텍스 출력 데이터로 사용할 수 있는 모든 것)
전통적으로 객체의 음영은 각 버텍스의 위치와 법선에 조명을 적용하여 계산되었으며, 그 결과로 나온 색상만 버텍스에 저장되었다. 그런 다음 이 색상은 삼각형 전체에 걸쳐 보간되었다.
이러한 이유로, 이 programable 한 unit을 버텍스 쉐이더라고 명명하게 되었다.
현대 GPU의 등장과 함께, 일부 또는 전체 쉐이딩이 픽셀 단위로 이루어지는 환경에서는 이 버텍스 쉐이딩 단계가 더 일반화되었으며, 음영 방정식이 프로그래머의 의도에 따라 평가되지 않을 수도 있다. 이제 버턱스 쉐이더는 각 버텍스와 연관된 데이터를 설정하는 데 전념하는 더 일반적인 유닛이 되었다.
먼저, 항상 필요한 좌표 세트인 버텍스 위치가 어떻게 계산되는지 알아보자. 모델이 화면에 표시되는 과정에서는 여러 공간이나 좌표계로 변환이 이루어진다. 처음에는 모델이 모델 공간 ( = 로컬 공간)에 위치하며 이는 변환이 전혀 이루어지지 않은 상태를 의미한다.
모델은 모델 변환 ( = 월드 변환)과 연결될 수 있는데, 이를 통해 모델의 위치와 방향을 조절할 수 있다. 또한, 하나의 모델에 여러 모델 변환을 적용하는 것도 가능하다. 이렇게 하면 동일한 모델을 복제하지 않고도, 같은 장면에서 모델의 여러 인스턴스가 서로 다른 위치, 방향, 크기를 가질 수 있다. (이러한 기법을 인스턴싱이라고 한다.)
모델 변환에 의해 변환되는 것은 모델의 버텍스와 법선이다. 객체의 좌표는 모델 좌표라고 불리며, 이 좌표에 모델 변환이 적용된 후에는 모델이 월드 좌표 또는 월드 공간에 위치한다고 한다.
모델 좌표는 객체마다 독립적으로 존재하지만 월드 공간은 고유하며, 각 모델에 해당하는 모델 변환이 적용된 후 모든 모델은 이 동일한 공간에 존재하게 된다.

앞서 언급했듯이, 카메라가 볼 수 있는 모델만 렌더링된다. 카메라는 월드 공간에서 위치와 방향을 가지며, 이를 통해 카메라를 배치하고 조준할 수 있다. 뷰 변환은 투영과 클리핑을 용이하게 하기 위해 카ㅔ라와 모든 모델을 변환하는 데 사용된다. 뷰 변환의 목적은 카메라를 원점에 배치하고, 카메라가 음수 z축 방향을 바라보도록 하며, y축은 위로, x축은 오른쪽으로 가리키게 만드는 것이다. 우리는 일반적으로 음수 축을 바라보는 관례를 사용하지만, 일부 문헌에서는 양수 z축을 사용하는 경우도 있다. 두 방식의 차이는 의미상의 차이일 뿐이며, 한쪽에서 다른 쪽으로의 변환은 그저 부호만 바꿔주면 된다.
뷰 변환이 적용된 후의 실제 위치와 방향은 기본적으로 사용하는 렌더링 API에 따라 달라진다. 이로 인해 형성된 공간은 카메라 공간 혹은 뷰 공간 혹은 아이 스페이스 (eye space)라고 불린다.
모델 변환과 뷰 변환은 모두 4x4 행렬로 구현될 수 있고 지금 이해해야 할 것은 버텍스 쉐이더에서 버텍스의 위치나 법선을 프로그래머가 선호하는 방식으로 계산할 수 있다는 점이다.
다음으로, 버텍스 쉐이딩의 두 번쨰 출력 유형에 대해서 설명하겠다. 현실감 있는 장면을 생성하려면 객체의 형태와 위치만 렌더링하는 것으로는 충분하지 않으며, 객체의 외형도 함께 모델링해야 한다. 이 외형에 대한 설명에는 각 객체의 재질(material) 뿐만 아니라, 객체에 비추는 광원 (light source) 효과도 포함된다.
재질과 광원은 단순한 색상부터 복잡한 물리적 특성을 표현하는 정교한 모델에 이르기까지 다양한 방식으로 모델링할 수 있다.
광원이 재질에 미치는 영향을 결정하는 작업을 쉐이딩이라고 한다. 쉐이딩은 객체의 다양한 지점에서 쉐이딩 방정식을 계산하는 과정을 포함한다. 일반적으로 이러한 계산 중 일부는 모델의 버텍스에서 지오메트리 프로세싱 중 수행되며, 나머지는 픽셀 단위 처리 (per-pixel processing) 에서 수행될 수 있다.
각 버텍스에는 쉐이딩 방정식을 평가하는 데 필요한 다양한 재질 데이터가 저장될 수 있다. 예를 들어, 버텍스의 위치, 법선, 색상, 기타 수치 정보 등이다.
버텍스 쉐이딩 결과는 래스터화 및 픽셀 처리 단계로 전달되며, 이 과정에서 보간되어 표면 쉐이딩을 계산하는 데 사용된다.
버텍스 쉐이딩의 일부로 렌더링 시스템은 투영과 클리핑 작업을 수행한다. 이 과정에서 뷰 볼륨은 극점이 (-1, -1, -1) 과 (1, ,1, 1)인 단위 큐브로 변환된다. 동일한 볼륨을 정의하기 위해 다른 범위도 사용될 수 있으며, [0, 1] 과 같은 범위가 사용되기도 한다. 이 단위 큐브를 Canonical view volume 이라고 부른다.

투영은 먼저 수행되며, GPU에서는 버텍스 쉐이더가 이를 처리한다. 일반적으로 사용되는 두 가지 투영 방식은 직교 투영과 원근 투영이다. 사실 직교 투영은 평행 투영의 한 종류에 불과하고, 건축 분야에서는 경사 투영, 축측 투영과 같은 평행 투영의 다른 형태도 널리 사용된다.
투영은 행렬로 표현되며, 다른 지오메트리 변환과 결합되어 처리된다.
직교 투영의 뷰 볼륨은 일반적으로 직사각형 박스 형태이며, 직교 투영은 이 뷰 볼륨을 단위 큐브로 변환한다. 직교 투영의 주요 특징은 변환 후에도 평행선이 평행을 유지한다는 점이다. 이 변환은 평행 이동과 스케일링의 조합으로 이루어진다.
반면, 원근 투영은 조금 더 복잡해지는데, 이 투영 방식에서는 카메라가 멀리 떨어질수록 객체가 작아 보이는 효과가 나타난다. 또한, 평행선이 지평선에서 수렴하는 것처럼 보일수도 있다. 원근 변환은 우리가 객체의 크기를 인식하는 방식을 모방한다. 기하학적으로 원근 투영의 뷰 볼륨은 frustum이라고 불리며, 이는 잘린 피라미드 형태이다. 이 프러스텀 역시 단위 큐브로 변환된다.
직교 변환과 원근 변환 모두 4x4 행렬로 구성될 수 있으며, 이러한 변환이 이루어진 후 모델은 클립 좌표에 위치한다고 한다. 클립 좌표는 사실 동차 좌표계이며, 이는 w로 나누기 전 단계에 해당한다. GPU의 버텍스 쉐이더는 다음 기능 단계인 클리핑이 올바르게 작동하도록 반드시 이러한 형태의 좌표를 출력해야 한다.
이 행렬들이 한 뷰 볼륨을 다른 뷰 볼륨으로 변환하지만, 이를 투영으로 부르는 이유는, 디스플레이 후 z좌표가 생성된 이미지에 저장되지 않고, 대신 z-버퍼에 저장되기 떄문이다. 이러한 방식으로 모델은 3차원에서 2차원으로 투영된다.
모든 파이프라인에는 앞서 설명한 버텍스 프로세싱이 포함되어 있다. 이 처리가 완료된 후, GPU는 몇가지 선택적인 프로세스를 수행할 수 있는데, 그것은 테셀레이션과 지오메트리 쉐이더, 스트림 출력 이다.
이 단계들의 사용 여부는 하드웨어 성능과 프로그래머의 의도에 따라 결정된다. 이들은 널리 사용되지는 않는다.
테셀레이션을 설명하기 위해 bounding ball 객체를 예로 들어보겠다. 공을 하나의 삼각형 집합으로 표현한다고 가정하면, 품질이나 성능 문제에 직면할 수 있다. 공은 5미터 거리에서는 잘 보일 수 있지만, 가까이에서 보면 개별 삼각형이 눈에 띌 수 있다. 이를 해결하기 위해 삼각형의 수를 늘려 공의 품질을 향상시키면, 공이 화면에서 몇 픽셀만 차지하는 먼 거리에서는 불필요하게 많은 처리 시간과 메모리를 낭비할 수 있다. 테셀레이션을 사용하면, 곡면을 적절한 삼각형 수로 생성하여 이러한 문제를 해결할 수 있다.
버텍스는 점, 선, 삼각형을 표현하는데 사용되지만, 공과 같은 곡면을 표현할 수도 있다. 이러한 곡면은 패치의 집합으로 정의될 수 있으며, 각 패치는 여러 버텍스로 구성된다.
테셀레이션 단계는 자체적으로 여러 하위 단계로 구성되며, 각각의 역할은 다음과 같다.
1. 헐 쉐이더 - 패치의 속성을 정의하고, 테세레이션 정도를 결정하는 데 필요한 정보를 제공한다.
2. 테셀레이터 - 패치를 더 작은 요소 (더 많은 버텍스 집합)으로 분할한다.
3. 도메인 쉐이더 - 생성된 새 버텍스를 기반으로 최종 곡면과 모양을 정의한다.
이 과정에서 ,생성되는 삼각형의 개수는 카메라를 기준으로 조정된다. 예를 들어, 패치가 카메라에 가까울 떄는 더 많은 삼각형이 생성되고, 멀리 있을 때는 더 적은 삼각형이 생성된다.
이렇게 하면 품질과 성능을 모두 최적화할 수 있다.
지오메트리 쉐이더는 테셀레이션 보다 더 일반적으로 사용된다. 지오메트리 쉐이더는 다양한 종류의 프리미티브를 입력받아 새로운 버텍스를 생성할 수 있다는 점에서 테셀레이션 쉐이더와 유사하다. 그러나 훨씬 단순한 단계로, 생성 범위가 제한적이며 출력 가능한 프리미티브 종류도 더 제한적이다.
지오메트리 쉐이더는 여러 용도로 사용되며 그중 가장 인기 있는 용도 중 하나는 파티클 생성이다. 예를 들어 폭죽 폭발을 시뮬레이션한다고 할 때, 지오메트리 쉐이더가 활용될 수 있다.
각 불꽃은 하나의 점, 단일 버텍스로 표현될 수 있다. 지오메트리 쉐이더는 이 점을 받아서, viewer 를 향해 정렬된 사각형 (두 개의 삼각형)을 생성할 수 있다. 이렇게 생성된 사각형은 여러 픽셀을 덮으며, 쉐이딩 하기에 더 적합한 프리미티브를 제공한다. 이를 통해 보다 설득력 있는 효과를 구현할 수 있다.
스트림 출력은 GPU를 지오메트리 엔진으로 활용할 수 있게 한다. 처리된 버텍스를 파이프라인의 나머지 과정으로 보내 화면에 렌더링하는 대신, 이 단계에서 선택적으로 버텍스를 배열로 출력하여 추가 처리를 수행할 수 있따.
출력된 데이터는 CPU 또는 GPU 이후 처리 단계에서 사용될 수 있다. 이 단계는 주로 파티클 시뮬레이션에서 사용되며, 예를 들어 앞서 설명한 폭죽 시뮬레이션에서 활용될 수 있다.
3가지 선택적 단계 테셀레이션, 지오메트리 쉐이딩, 스트림 출력은 이 순서로 실행되며, 각 단계는 선택적으로 사용할 수 있따. 어떤 옵션을 사용하든 아니든, 파이프라인의 다음 과정으로 넘어가면 동차 좌표로 표현된 버텍스 집합이 생성된다. 이후에는 카메라가 이들을 볼 수 있는지 확인하는 단계가 진행된다.
클리핑
뷰 볼륨 내부에 완전히 또는 부분적으로 포함된 프리미티브 만이 레스터화 단계와 그 이후의 픽셀 처리 단계로 전달되어 화면에 그려진다. 뷰 볼륨 내부에 완전히 포함된 프리미티브는 그대로 다음 단계로 전달된다만, 뷰 볼륨 외부에 완전히 위치한 프리미티브는 렌더링되지 않기 떄문에 더 이상 처리되지 않는다. 뷰 볼륨에 부분적으로 걸친 프리미티브는 클리핑이 필요하다. 예를 들어, 하나의 버텍스가 뷰 볼륨 밖에 있고 다른 하나는 뷰 볼륨 안에 있는 선의 경우, 뷰 볼륨에 대해 클리핑되어야 한다. 이 과정에서 뷰 볼륨 밖에 있는 버텍스는 선과 뷰 볼륨의 교차점에 위치한 새로운 버텍스로 대체된다.
투영 행렬을 사용하는 경우, 변환된 프리미티브는 단위 큐브에 대해 클리핑된다. 뷰 변환과 투영을 클리핑 전에 수행하는 이점은 클리핑 문제를 일관되게 유지할 수 있다는 점이다. 즉, 모든 프리미티브가 항상 단위 큐브에 대해 클리핑되므로 처리 방식이 표준화 된다.
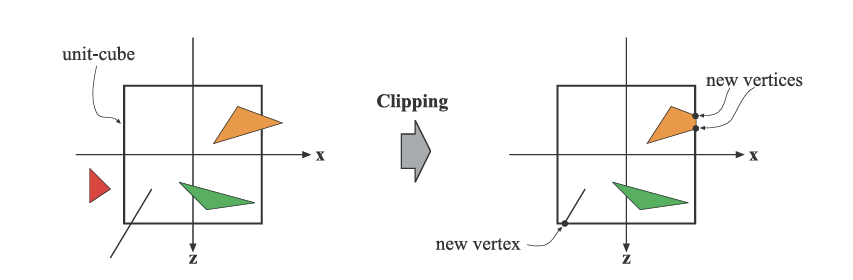
클리핑 과정을 시각적으로 나타내면 위와 같다.
여섯 개의 클리핑 평면 외에도 사용자가 임의로 클리핑 평면을 정의하여 객체를 잘라낼 수 있따.
이러한 유형의 시각화를 단면화라고 한다.
클리핑 단계에서는 투영에 의해 생성된 4개의 값으로 구성된 동차 좌표를 사용하여 클리핑 작업을 수행한다. 일반저그올 원근 공간에서 삼각형의 값들은 선형적으로 보간되지 않는다. (원근 투영 보간 참조) 따라서 데이터가 정확히 보간되고 클리핑되도록 하기 위해 네 번쨰 좌표가 필요하다.
마지막으로, 원근 분할 (Perspective division) 이 수행된다. 이 과정에서 결과로 나온 삼각형의 위치를 3차원 정규화 장치 좌표 (NDC) 로 변환한다. 앞서 언급했듯이, 이 뷰 볼륨은 (-1, -1, -1) 에서 (1, 1, 1) 까지의 범위를 가진다.
지오메트리 단계의 마지막 단계는 이 정규화된 좌표를 윈도우 좌표계로 변환하는 것이다.
스크린 매핑
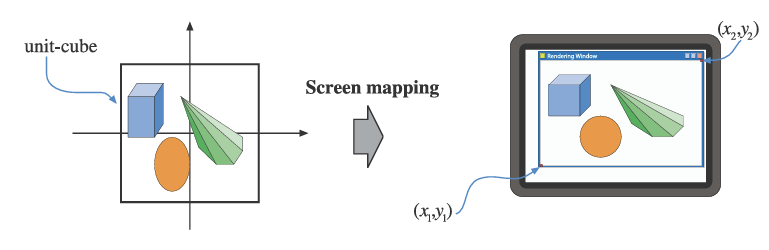
클리핑된 뷰 볼륨 내부의 프리미티브만 스크린 매핑 단계로 전달되며, 이 단계에 들어갈 때의 좌표는 여전히 3차원 상태이다. 각 프리미티브의 x-좌표 y-좌표는 화면 좌표로 변환된다. 화면 좌표는 z좌표와 함께 윈도우 좌표라고도 불린다.
예를 들어, 장면의 최소 코너가 (x1, y1) 최대 코너가 (x2, y2) 인 창에 렌더링된다고 가정하자.
화면 매핑은 평행 이동 후 스케일링 작업을 통해 이루어진다. 변환된 x, y 좌표는 화면 좌표로 정의된다.
z좌표는 OpenGL의 경우 [-1, +1] Dx의 경우 [0, 1] 범위를 가지며, 이는 [z1, z2]로 매핑된다. 변환된 윈도우 좌표과 z값은 레스터화 단계로 전달된다.
다음으로, 정수 값과 부동소수점 값이 픽셀 및 텍스처 좌표와 어떻게 연관되는지 설명하겠다.
수평 배열의 픽셀이 있다고 가정하고 이를 데카르트 좌표계를 사용해 표현할 때, 가장 왼쪽 픽셀의 왼쪽 경계선은 부동소수점 좌표에서 0.0 에 해당한다. OpenGL은 항상 이 좌표 시스템을 사용해왔으며, DirectX 10과 그 이후 버전도 이를 채택하고 있다.

해당 픽셀의 중앙은 0.5에 위치한다. 따라서, [0, 9] 범위의 픽셀은 부동소수점 좌표로 [0.0, 10.0) 의 구간을 덮는다.
변환은 간단하며, 정수 값과 부동소수점 값 사이의 관계를 이 기준에 따라 계산할 수 있다.
모든 API에서 픽셀 위치 값은 왼쪽에서 오른쪽으로 갈수록 증가하지만, 위쪽과 아래쪽 경계의 기준점 위치는 OpenGL과 DirectX 간에 경우에 따라 다를 수 있다.
OpenGL은 데카르트 좌표계를 일관되게 유지하며, 이미지의 왼쪽 아래 코너를 최소값으로 간주한다. 반면, DirectX는 문맥에 따라 이미지의 왼쪽 위 코너를 최솟값으로 정의한다.
이러한 차이는 각 방식에 나름의 논리가 존재하며, 어느 방식이 옳다고 말할 수 없다.
API 간 전환 작업을 수행할 때, 이러한 차이를 반드시 고려해야만 올바른 좌표 처리를 보장할 수 있다.
레스터화
변환되고 투영된 버텍스와 그에 연관된 쉐이딩 데이터를 가지고 다음 단계의 목표는 렌더링되는 프리미티브 내부에 있는 모든 픽셀을 찾는 것이다. 이 과정을 래스터화라고 하며, 두 개의 기능적 하위 단계로 나뉜다.
하나는 Triangle Setup, 나머지는 Triangle Traversal이다.
이 과정은 점과 선도 처리할 수 있지만, 삼각형이 가장 일반적이기 때문에 하위 단계 이름에 삼각형이라는 용어가 포함되어 있다.

래스터화는 스캔 변환이라고도 하며, 스크린 공간의 2차원 버텍스들을 화면 픽셀로 변환하는 과정이다.
또한, 레스터화는 기하학 처리와 픽셀 처리 사이의 동기화 지점으로 볼 수도 있다. 이 단계에서 세 개의 버텍스로 삼각형이 구성되며, 이후 픽셀 처리 단계로 전달된다.
삼각형이 픽셀과 겹치는지 여부는 GPU 파이프라인을 어떻게 설정했는지에 따라 달라진다. 예를들어, 삼각형의 내부 여부를 결정하기 위해 포인트 샘플링을 사용할 수 있다. 가장 단순한 경우는 각 픽셀의 중앙에서 단일 포인트 샘플을 사용하는 방식이다. 이 경우, 픽셀 중앙의 샘플 포인트가 삼각형 내부에 있으면 해당 필셀로 삼각형 내부로 간주된다.
또한, 슈퍼샘플링, 멀티샘플링 안티앨리어싱 기술을 사용하여 픽셀당 여러 샘플을 적용할 수도 있으며, 이를 통해 더욱 정교한 결과를 얻을 수 있다.
또 다른 방식으로는 보수적 래스터화를 사용할 수 있는데, 이 방법에서는 픽셀의 일부라도 삼각형과 겹친다면 해당 픽셀을 삼각형 내부로 간주한다. 이러한 방식은 삼각형이 픽셀을 포함하는 기준을 더 넓게 설정하여 더 정확할 처리 결과를 얻을 수 있다.
Triangle Setup의 주 목적은 삼각형 내뷰애 포함된 픽셀을 결장하기 위해 삼각형의 경계를 정의하는 방정식을 계산하는 것이다. 이것을 엣지 방정식이라고 부른다. 뿐만 아리나 삼각형의 미분값과 같은 기타 데이터를 계산한다. 이러한 데이터는 triangle tracersal에 사용될 뿐만 아니라 Geometry Stage에서 생성된 다양한 쉐이딩 데이터를 보간하는데도 활용된다.
이 작업은 고정 기능 하드웨어를 사용하여 수행된다.
Trangle Traversal 단계에서는 삼각형이 덮고 있는 픽셀의 중심을 확인하고, 삼각형과 겹치는 부분에 대해 프래그먼트를 생성한다. 삼각형 내부에 있는 픽셀을 찾는 과정을 삼각형 탐색이라고 한다. 각 삼각형 프래그먼트의 속성은 삼각형의 세 버텍스 사이에서 보간된 데이터를 사용해 생성된다. 이러한 속성에는 프래그먼트의 깊이뿐만 아니라 지오메트리 프로세싱 단계에서 생성된 쉐이딩 데이터도 포함된다.
또한, 이 단계에서 삼각형에 대해 원근 보정 보간이 수행된다.
프리미티브 내부에 있는 모든 픽셀이나 샘플은 다음 단계인 픽셀 프로세싱 스테이지로 전달된다.
픽셀 프로세싱
이 단계에서는 삼각형 또는 다른 프리미티브 내부에 있는 모든 픽셀이 이전 모든 단계의 결합 결과로 식별된다. 픽셀 처리 단계는 픽셀 쉐이딩, 머징 의 두 단계로 나뉜다. 픽셀 처리 단계는 프리미티브 내부에 있는 픽셀에 대해 픽셀 단위(per pixel)로 계산과 작업이 수행되는 단계이다. 이 과정에서 프래그먼트의 쉐이딩 데이터가 처리되고, 이후 결과가 다른 프래그먼트 데이터와 결합되거나 화면 버퍼에 병합된다.
픽셀 쉐이딩 단계에서는 픽셀 단위 쉐이딩 계산이 수행되며, 입력으로는 이전 단계에 보간된 쉐이딩 데이터가 사용된다. 최종 결과물은 하나 이상의 색상 값으로 다음 단계로 전달된다. triangle setup과 triangle traversal 단계가 주로 전용 하드웨어에 의해 수행되는 반면, 픽셀 쉐이딩 단계는 programmable GPU cores 에서 실행되기에, 이로그래머는 픽셀 쉐이더에서 사용할 프로그램을 작성하여 원하는 계산을 수행할 수 있다. 이 단계에서 다양한 기술을 사용할 수 있으며, 그중 가장 중요한 것 중 하나는 텍스처링이다. 텍스처링은 객체에 하나 이상의 이미지를 붙이는 과정으로, 여러 목적으로 사용된다. 이미지는 1차원, 2차원 또는 3차원일 수 있으며, 2차원 이미지가 가장 일반적으로 사용된다. 기본적으로 이 과정의 최종 산출물은 각 프래그먼트의 색상 값이며, 이 값은 다음 하위 단계로 전달된다.
병합
픽셀 정보는 컬러 버퍼에 저장되며, 이는 직사각형 배열로 구성된다. 이 배열의 각 색상은 빨강, 초록, 파랑 구성 요소를 포함한다. 병합 단계의 주요 역할은 픽셀 쉐이딩 단계에서 생성된 프래그먼트 색상을 컬러 버퍼에 현재 저장된 색상과 결합하는 것이다. 이 단계는 ROP라고도 불리며, 이는 래스터 연산 또는 렌더 출력 유닛의 약자를 의미한다.
병합 단계는 쉐이딩 단계와는 다르게 GPU의 서브유닛이 수행하며 일반적으로 프로그래밍이 불가능하다. 하지만 이 단계는 구성이 매우 유연하기에 다양한 그래픽 효과를 구현할 수 있다.
이 단계는 가시성을 해결하는 역할을 한다. 이는 카메라가 보는 프래그먼트만 컬러 버퍼에 저장한다는 것을 의미한다. 대부분의 그래픽 하드웨어에서 이 작업을 z버퍼 알고리즘을 사용하여 수행된다.
z 버퍼는 컬러 버퍼와 동일한 크기와 형태를 가지며, 각 픽셀에 대해 현재 가장 가까운 프리미티브의 z값(깊이 값)을 저장한다. 즉, 특정 픽셀에 프리미티브를 렌더링할 때, 해당 픽셀에서 프리미티브의 z값이 계산되고 z버퍼에 저장된 기존 z값과 비교된다. 만약 새 z값이 z버퍼의 값보다 작다면, 이는 현재 렌더링 중인 프리미티브가 그 픽셀에서 이전에 가장 가까웠던 프리미티브보다 카메라에 더 가깝다는 것을 의미한다. 따라서, z버퍼와 컬러버퍼의 값이 현재 프리미티브의 z값과 색상으로 업데이트된다. 반면, 계싼된 z값이 z버퍼의 값보다 크다면, 컬러 버퍼와 z버퍼는 변경되지 않고 그래도 유지된다. (깊이 테스트)
z버퍼 알고리즘은 단순하며, O(n)의 복잡도를 가지고 있다. 또한, 이 알고리즘은 대부분의 프리미티브를 렌더링 순서와 관계없이 처리할 수 있기에 매우 인기가 많다. 하지만, z버퍼는 화면의 각 지점에서 단일 깊이 값만 저장하므로, 부분적으로 투명한 프리미티브를 처리할 수 없다. 이러한 경우, 불투명한 프리미티브를 먼저 렌더링하고, 투명한 프리미티브는 뒤~앞 순서로 렌더링하거나, 별도의 순서 독립적 알고리즘을 사용해야한다.
투명도는 z버퍼 알고리즘의 주요 약점 중 하나이다.
우리는 컬러 버퍼가 색상을 저장하고 z-버퍼가 각 픽셀의 z-값을 저장한다고 언급하였다. 그러나 프래그먼트 정보를 필터링하고 캡처하기 위해 사용할 수 있는 다른 채널과 버퍼들도 존재한다. 알파 채널은 컬러 버퍼와 연관되어 있으며, 각 픽셀의 투명도값을 저장한다. 예전 API에서는 알파 채널이 알파 테스트 기능을 통해 픽셀을 선택적으로 폐기하는 데 사용되기 도 했으나, 현재는 픽셀 쉐이더 프로그램에 discard 연산을 삽입하여, 어떤 유형의 계산도 픽셀을 폐기하는 조건으로 사용할 수 있따. 이러한 테스트는 완전히 투명한 프래그먼트가 z버퍼에 영향을 미치지 않도록 보장하는 데 사용된다.
스텐실 버퍼는 렌더링된 프리미티브의 위치를 기록하는 데 사용되는 오프스크린 버퍼이다. 오프스크린 렌더링이란 화면에 표시하지 않고 다른 텍스처나 버퍼에 렌더링하는 것을 의미한다. 스텐실 버퍼는 오프스크린 렌더링을 구현하는 버퍼 중 하나이다. 일반적으로 픽셀당 8비트를 포함한다. 프리미티브는 다양한 함수로 스텐실 버퍼에 렌더링 될 수 있으며, 그 후 버퍼의 내용을 활용해 컬러 버퍼와 z버퍼의 렌더링을 제어할 수 있다.
예를 들어, 스텐실 버퍼에 채워진 원을 그렸다고 가정해보자. 이 원의 영역과 연산자를 결합하면, 이후 렌더링되는 프리미티브가 원이 있는 위치에서만 컬러 버퍼에 렌더링되도록 할 수 있다. 스텐실 버퍼는 특정 특수 효과를 생성하는 강력한 도구가 될 수 있다.
파이프라인 마지막에 있는 이러한 모든 기능은 래스터 연산(ROP, Raster Operations) 또는 블렌드 연산이라고 불린다. 현재 컬러 버퍼에 있는 색상과 삼각형 내부에서 처리중인 픽셀의 색상을 혼합할 수 있으며, 이를 통해 투명도나 색상 샘플의 누적과 같은 효과를 구현할 수 있다. 앞서 언급했듯이, 블렌딩은 API를 통해 구성 가능하며, 완전히 프로그래밍 가능한 것은 아니다. 그러나 일부 API는 래스터 순서 뷰, 픽셀 쉐이더 순서를 지원하여 프로그래밍 가능한 블렌딩 기능을 제공한다.
프레임버퍼(실질적으로 보이는 렌더 타켓)는 시스템의 모든 버퍼로 구성된다. 프리미티브가 래스터화 단계를 통과한 후, 카메라의 관점에서 보이는 프리미티브들은 화면에 표시된다. 이때 화면은 컬러 버퍼의 내용을 표시한다. 그러나, 프리미티브가 래스터화되고 화면에 전송되는 과정을 사람이 볼 수 없도록 하기 위해 더블 버퍼링이 사용된다.
더블 버퍼링에서는 장면의 렌더링 화면 밖의 백 버퍼에서 이루어진다. 장면이 백 버퍼에 렌더링되면, 백 버퍼의 내용이 이전에 확면에 표시되었던 프론트 버퍼의 내용과 교환된다. 버퍼 교환은 종종 안전하게 수행할 수 있는 수직 동기신호 동안에발생한다.
파이프라인을 통한 흐름
점, 선, 삼각형은 모델이나 객체를 구성하는 렌더링 프리미티브이다. 예를 들어 응용 프로그램이 CAD같은 소프트웨어이고, 사용자가 와플 기계의 설계를 살펴보고 있다고 가정하자. 여기서는 이 모델이 그래픽 렌더링 파이프라인의 네 가지 주요 단계(애플리케이션, 지오메트리 프로세싱, 래스터화, 픽셀 프로세싱)을 거치는 과정을 따라가 보겠다.
장면은 원근 투영으로 렌더링되어 화면의 창에 표시된다. 이 간단한 예에서, 와플 기계 모델은 부품의 가장자리를 보여주기 위해 선, 표면을 보여주기 위해 삼각형을 원근 투영하여 렌더링한다. 와플 기계에는 열 수 없는 뚜껑이 있으며, 일부 삼각형에는 제조사의 로고가 포함된 2차원 이미지로 텍스처가 입혀져 있따.
이 예에서 표면 쉐이딩은 텍스처 적용을 제외하고는 지오메트리 프로세싱 단계에서 완전히 계산된다. 텍스처는 래스터화 단계에서 적용된다.
애플리케이션
CAD 애플리케이션은 사용자가 모델의 일부를 선택하고 이동할 수 있도록 한다. 예를 들어, 사용자가 뚜껑을 선택한 후 마우스를 움직여 뚜껑을 열도록 할 수 있다. 애플리케이션 단계에서 마우스 움직임을 적절한 회전 행렬로 변환하고, 이 행렬이 렌더링 시 뚜껑에 제대로 적용되도록 해야 한다.
또 다른 예로, 애니메이션이 실행되어 카메라가 사전에 저의된 경오를 따라 이동하며 와플 기계를 여러 시점에서 보여주는 경우를 들 수 있다. 이때 카메라의 매개변수는 시간에 따라 애플리케이션에서 업데이트되어야 한다.
렌더링될 각 프레임에 대해 애플리케이션 단계는 카메라 위치, 조명, 그리고 모델의 프리미티브를 파이프라인의 다음 주요 단계인 지오메트리 단계로 전달한다.
지오메트리 프로세싱
원근 투영을 위해, 애플리케이션이 투영 행렬을 제공했다고 가정하자. 또한, 각 객체에 대해 뷰 변환과 객체의 위치 및 방향을 설명하는 행렬(모델링 행렬)을 애플리케이션이 계산한다. 예를 들어, 와플 기계의 밑면은 하나의 행렬을 가지며, 뚜껑은 또 다른 행렬을 가진다.
지오메트리 단계에서는 객체의 버텍스와 법선이 이 행렬로 변환되어 객체를 뷰 공간으로 배치한다. 이후, 재질 및 광원 속성을 사용해 버텍스에서 쉐이딩이나 기타 계산을 수행할 수 있다.
그 다음, 별도로 제공된 투영 행렬을 사용하여 객체를 단위 큐브 공간으로 변환한다. 이 단위 큐브는 눈에 보이는 장면을 나타낸다. 단위 큐브 바깥에 있는 모든 프리미티브는 폐기된다. 단위 큐브와 교차하는 프리미티브는 단위 큐브에 대해 클리핑되어 큐브 내부에 완전히 위치한 프리미티브 세트가 만들어진다.
그 후, 버텍스는 화면의 창으로 매핑된다. 이러한 삼각형 단위 및 버텍스 단위의 모든 작업이 완료되면, 결과 데이터가 레스터화 단계로 전달된다.
레스터화
이전 단계에서 클리핑을 통과한 모든 프리미티브는 레스터화 과정을 거친다. 이 과정에서는 프리미티브 내부에 있는 모든 픽셀을 찾아내어 파이프라인의 다음 단계인 픽셀 프로세싱 단계로 전달한다.
픽셀 처리
이 단계의 목표는 각 보이는 프리미티브의 각 픽셀에 대한 색상을 계산하는 것이다. 텍스처 이미지가 적용된 삼각형은 원하는 방식으로 텍스처가 적용된 상태로 렌더링된다.
카시성을 z버퍼 알고리즘을 사용하여 해결되며, 선택적으로 폐기(discard) 및 스텐실 테스트가 수행된다. 각 객체는 순서대로 처리되며, 최종적으로 생성된 이미지는 화면에 표시된다.
결론
이 렌더링 파이프라인은 실시간 렌더링 애플리케이션을 목표로 한 API와 그래픽 하드웨어의 수십 년 간의 진화를 통해 만들어졌다. 그러나, 이것이 유일한 렌더링 파이프라인은 아니다. 오프라인 렌더링 파이프라인은 다른 진화 과정을 거쳤다. 예를 들어, 영화 제작용 렌더링은 종종 마이크로 폴리곤 파이프라인을 사용했지만, 최근에는 레이 트레이싱과 패스 트레이싱이 이를 대체하고 있다.
오랜 기간 동안, 애플리케이션 개발자들은 여기서 설명된 과정을 사용하는 유일한 방법으로, 사용 중인 그래픽 API에 의해 정의된 고정 기능 파이프라인을 사용해야 했다. 고정 기능 파이프라인은 그래픽 하드웨어가 유연하게 프로그래밍될 수 없는 요소들로 구성되어 있기 떄문에 그렇게 불린다.
반면, Programmable GPU는 파이프라인의 다양한 하위 단계에서 어떤 작업을 적용할지 정확히 결정할 수 있게 해준다. 이 책의 모든 개발은 Programmable GPU를 사용하여 이루어진다고 가정하고 설명한다.
'컴퓨터 그래픽스' 카테고리의 다른 글
| PBR 물리 기반 렌더링 + 모델 로딩 + 반사 테스트 (0) | 2025.02.27 |
|---|---|
| 컴퓨트 쉐이더를 이용한 Smoothed Particle Hydrodynamics Fluid (0) | 2025.02.25 |
| [Real-time Rendering] Chapter 1. Introduction (1) | 2025.01.23 |
| 직접 만든 그래픽 엔진으로 여러가지 출력 (1) | 2024.09.05 |
| [그래픽스] 구형 선형 보간으로 회전 보간 (0) | 2024.08.27 |